ملف بارسيفيل
الوظيفة | تحليل ملف للحصول على نص و/أو قيم، وإنشاء قيم تفاضلية. يمكن تحليل ما يصل إلى 32 قيمة / قيمة سلسلة / قيمة تفاضلية / قيمة معدل / مقارنة نتائج / عدادات مطابقة وأحداث لكل مهمة تحليل. |
|---|---|
التنبيه | مطابقات السلسلة، عدد السلاسل، القيم، قيم السلسلة، قيم التفاضل، قيم المعدل، الأحداث، عمر الملف، عمر محتوى الملف، رمز الاستجابة خاص: يمكن أن تدخل المهمة في حالة صيانة جيدة أو صيانة كبيرة، بناءً على حدود الإنذار المكونة. |
تفاصيل ملف التحليل
معلمات ملف التحليل
المعلمة | الوصف |
|---|---|
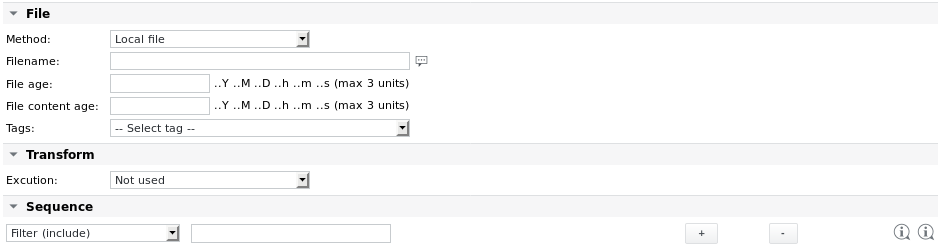
الطريقة | يمكن أن يكون الملف المراد تحليله ملفًا محليًا (افتراضيًا) أو يمكن جلبه أولاً باستخدام أحد البروتوكولات التالية: HTTP إذا تم اختيار أحد البروتوكولات البعيدة، فسيتم عرض معلمات إضافية لمسار المصدر ومصادقة المستخدم. انظر مهمة Fetchfile للحصول على تفاصيل التكوين. مثال: جلب الملف أولاً من خادم الويب، قبل تحليله: يُفضل جلب ملف بعيد من داخل مهمة Parsefile. هناك طريقة بديلة تتمثل في إنشاء مهمة دفعية باستخدام مهمة Fetchfile أو Agent Fetchfile ومهمة Parsefile. إذا كان النظام البعيد يعمل على Windows وتم تثبيت SKOOR WinAgent، فيمكن أيضًا جلب الملفات باستخدام WinAgent. يتم إدراج WinAgent في القائمة المنسدلة للطريقة، بمجرد تعيين خصائص اسم المستخدم وكلمة مرور الوكيل على جهاز المهام. في Windows 10، يمكن تثبيت خادم OpenSSH من الميزات الاختيارية. بعد بدء الخدمة المعنية، يمكن نسخ الملفات باستخدام scp. |
اسم الملف | اسم الملف المراد تحليله. يمكن تحديد المسار بالنسبة إلى دليل التحليل الافتراضي على المجمع (المحدد في الملف /etc/opt/eranger/eranger-collector.cfg، والذي يتم تعيينه عادةً إلى /var/opt/run/eranger/collector/tmp) أو بشكل مطلق. إذا كان الملف موجودًا في دليل فرعي للدليل الافتراضي المُعد، فيمكن إدخال اسم الملف على النحو التالي: subdir/file.txt |
عمر الملف | يختبر تاريخ ووقت آخر وصول إلى الملف. إذا كان أقدم من القيمة المحددة، فإن المهمة تصدر تحذيرًا (الملف قديم جدًا). يمكن إدخال عمر الملف بالدقائق أو الثواني، كما يتم دعم تنسيقات مثل "1h 30m". |
عمر محتوى الملف | يختبر ما إذا كان محتوى الملف قد تغير. إذا لم يتغير خلال الوقت المدخل هنا، فإن المهمة تصدر تحذيرًا (محتوى الملف قديم جدًا). تنسيق عمر محتوى الملف هو نفسه تنسيق معلمة عمر الملف. |
تحويل → تنفيذ | إذا كان التحويل التلقائي الذي توفره المهمة غير كافٍ لسبب ما، فيمكن معالجة الملف مسبقًا بواسطة أحد الخيارات التالية قبل تحليله: غير مستخدم (بدون معالجة مسبقة) |
التسلسل | انظر القسم التالي |
تسمح القائمة المنسدلة "العلامات" بإدخال متغيرات محددة مسبقًا في الحقول أعلاه، على سبيل المثال $NAME$ لاسم المهمة.
تحويلات الملفات القياسية
إذا تم جلب ملف من نظام آخر غير لينكس، فيجب تكييف بعض الأحرف الخاصة من أجل التحليل. توضح القائمة التالية الحالات التي يتم التعامل معها تلقائيًا بواسطة المهمة:
يتم إزالة أحرف إرجاع الحامل في Windows (كان يتم ذلك سابقًا بواسطة خيار التحويل dos2unix)
إذا كان الملف مشفرًا بتنسيق UTF-8 مع BOM (علامة ترتيب البايت)، تتم إزالة BOM
إذا كان الملف مشفرًا في unicode (big-endian UTF-16 أو little-endian UTF-16)
إذا لم يتم تعريف أي تحويل، يتم تحويل الملف إلى UTF-8 قبل التحليل
إذا تم تعريف تحويل، فلن يتم إجراء أي شيء على الملف (يُفترض أن التحويل يعالج الملف بشكل صحيح)
في حالة فشل التحويل، ستعرض رموز الاستجابة والخطأ الخاصة بالمهمة الرسائل التالية:
سيتم دائمًا عرض رمز الاستجابة 11 (فشل تحويل الملف) ويجب تكوينه كحد إنذار
يمكن عرض رمز الخطأ 1 (خطأ في النظام) أو 2 (خطأ داخلي) بشكل إضافي
تسلسل تحليل الملف
السلوك العام
إذا لم يتم العثور على الملف، يتم تعيين رمز الاستجابة على 1 (لم يتم العثور على الملف) ويتم إنهاء التنفيذ.
إذا تم تحديد عمر الملف و/أو عمر محتوى الملف، يتم إجراء هذه الفحوصات قبل تحليل الملف.
إذا كان الملف قديمًا جدًا، يتم تعيين رمز الاستجابة على 2 (الملف قديم جدًا)، ولكن لا يزال يتم تحليل الملف.
إذا كان محتوى الملف قديمًا جدًا، يتم تعيين رمز الاستجابة على 3 (محتوى الملف قديم جدًا)، ولكن لا يزال يتم تحليل الملف.
إذا كان الملف يحتوي على أكثر من 100000 سطر، يتم تعيين رمز الاستجابة على 4 (الملف طويل جدًا) ويتم إنهاء التنفيذ. يمكن رفع الحد الافتراضي أو إزالته عن طريق إضافة السطر التالي في ملف تكوين محرك SKOOR /opt/eranger/etc/eranger-collector.cfg:
parsefile_line_limit = 1000000 raise limit to a million lines parsefile_line_limit = 0 remove limit altogether
عند إضافة قيم جديدة وقيم سلاسل وقيم Diff وما إلى ذلك، يمكن إدخال 32 قيمة كحد أقصى في تسلسل التحليل لكل نوع من أنواع القيم. على سبيل المثال، عند إضافة 3 قيم باستخدام عنصر Get value، ابدأ بإضافة Get value مع الفهرس 1، ثم 2، ثم 3، مع زيادة عدد الفهارس. تسمح واجهة المستخدم فقط بتحديد مؤشر أقصى بناءً على عدد عناصر التسلسل المكونة حاليًا حتى لا تشغل قائمة اختيار المؤشر المنسدلة مساحة كبيرة.
العناصر المتاحة في القائمة المنسدلة لفلتر التسلسل
تعيين
تصفية (تضمين)
يتم تجاهل جميع الأسطر في الملف التي لا تحتوي على التعبير، على سبيل المثال، عند إدخال "localhost" (بدون علامات اقتباس) سيتم النظر فقط في الأسطر التي تحتوي على "localhost"؛ ويتم تخطي الأسطر الأخرى.
مرشح (استبعاد)
يعمل هذا بطريقة عكسية، أي كمرشح سلبي.
يتم تجاهل جميع الأسطر التي تحتوي على التعبير عند تحليل بقية التسلسل.
تحديد الفاصل
الفاصل الافتراضي للأعمدة هو المسافة البيضاء (مسافة واحدة، عدة مسافات متتالية، علامات جدولة). وهذا يقسم الأسطر إلى كلمات بشكل فعال.
يمكن اختيار فاصل مختلف هنا. أدخل سلسلة من حرف واحد أو أكثر مثل "؛" أو "COL". أثناء التسلسل، يمكن تعيين الفاصل وإعادة تعيينه عدة مرات. لإعادة التعيين، اترك حقل النص فارغًا.
يبدأ عدد الأعمدة من 0 (صفر).
وضع سجل النظام
إذا تم تعيين هذا، يستمر التحليل مع أول سطر جديد في الملف تمت إضافته منذ آخر تشغيل للمهمة.
إذا تم تدوير الملف، يتم استخدام الملف المدور من آخر موضع EOF حتى لا يتم فقدان أي بيانات.
تجاهل حالة الأحرف
إذا تم تعيين هذا الخيار، يتم تجاهل حالة الأحرف عند مقارنة السلاسل.
تجاهل غير موجود
إذا لم يتم العثور على سطر أو تعبير أو عمود، لا يتم تعيين رمز الاستجابة إلى 7 سلسلة غير موجودة، ولكن يتم إنهاء تنفيذ المهمة.
المتابعة بعد عدم العثور
إذا تم تعيين هذا الخيار، يتم متابعة التحليل بعد عدم العثور على سطر أو عمود.
كشف التجاوز/إيقاف
إذا تم تمكين هذا الخيار، فإن أي معلمات قيمة Diff تالية في التسلسل ستتجاهل القيم الأقل من القيمة المقاسة في تنفيذ المهمة السابقة (يُسمح بالاختلافات الموجبة فقط).
يستخدم هذا في الغالب للعدادات. يمكن إيقاف تشغيل الإعداد لاحقًا في التسلسل.
الحصول على الطابع الزمني (المعدل)
يمكن قراءة الطابع الزمني من ملف لإجراء حسابات دقيقة باستخدام معلمة التسلسل الحصول على قيمة المعدل. على سبيل المثال، إذا تم إنشاء الملف الذي تم تحليله بواسطة تطبيق يتم تنفيذه بشكل غير متزامن.
يجب طباعة الطابع الزمني في الملف بوحدات ثانية أو مللي ثانية أو ميكروثانية.
البحث تشير
المعلمات التالية إلى الأسطر. نطاق المعلمة التالية هو السطر الذي تم العثور عليه بواسطة المعلمة الحالية. إذا لم يكن السطر المطلوب موجودًا، يتم تعيين رمز الاستجابة على 5 (لم يتم العثور على السطر) ويتم إنهاء التنفيذ، إلا إذا تم تعيين "متابعة بعد عدم العثور".انتقل إلى السطر رقم
يتم وضع مؤشر التحليل في بداية السطر المقابل.
انتقل إلى السطر التالي
يتم وضع مؤشر التحليل في بداية السطر التالي.
انتقل إلى السطر الأول الذي يحتوي على
يتم وضع مؤشر التحليل في بداية السطر الأول الذي يقيّم السلسلة/التعبير.
إذا تعذر العثور على سطر يحتوي على مثل هذا التعبير وتم تعيين "متابعة بعد عدم العثور"، يتم وضع مؤشر التحليل في الحرف الأول من الصف الأول في الملف ويتم معالجة بقية التسلسل.
انتقل إلى السطر التالي مع
يتم وضع مؤشر التحليل في بداية السطر التالي الذي يقيّم السلسلة/التعبير.
إذا تعذر العثور على سطر يحتوي على مثل هذا التعبير وتم تعيين "متابعة بعد عدم العثور"، يتم وضع مؤشر التحليل عند الحرف الأول من الصف التالي ويتم معالجة بقية التسلسل.
انتقل إلى السطر الأخير باستخدام
يتم وضع مؤشر التحليل في بداية السطر الأخير الذي يقيّم السلسلة/التعبير.
إذا تعذر العثور على سطر يحتوي على مثل هذا التعبير وتم تعيين "متابعة بعد عدم العثور"، يتم وضع مؤشر التحليل عند الحرف الأول من الصف الأول في الملف ويتم معالجة بقية التسلسل.
البحث عن الفاصل بناءً على تعتمد
الأوامر التالية على تعريف الفاصل. إذا لم يتم تعريف أي فاصل، يتم استخدام المسافات البيضاء (المسافات أو علامات الجدولة) كفاصلالانتقال إلى العمود رقم
يتم وضع مؤشر التحليل عند الحرف الأول من العمود المقابل (0..n) في السطر الحالي.
إذا لم يتم العثور على العمود، يتم تعيين رمز الاستجابة على 6 (لم يتم العثور على العمود) ويتم إنهاء التنفيذ.
إذا لم يتم العثور على العمود وتم تعيين "متابعة بعد عدم العثور"، لا يتم تغيير موضع مؤشر التحليل.
يكون نطاق أوامر السلسلة التالية افتراضيًا هو الملف بأكمله؛ إذا تم استدعاء أحد أوامر السطر مسبقًا، يكون النطاق هو السطر الحالي.
إذا تم ترك الحقل فارغًا، يتم تعيين رمز الخطأ على 7 (معلمة غير صالحة) ويتم إنهاء التنفيذ.
انتقل إلى أول سلسلة
بناءً على النطاق، يتم البحث عن أول ظهور للسلسلة في الملف بأكمله / في السطر الحالي الذي يقيّم التعبير.
إذا تم العثور عليه، يتم وضع مؤشر التحليل عند الحرف الأول الذي يقيّم التعبير ثم يتم زيادته بطول التعبير
وإلا يتم إنهاء التنفيذ ويتم تعيين رمز الاستجابة على 7 (لم يتم العثور على السلسلة)، إلا إذا تم تعيين تجاهل عدم العثور أو متابعة بعد عدم العثور أعلاه.
الانتقال إلى السلسلة التالية
كما هو مذكور أعلاه، ولكن البحث يبدأ من الموضع الحالي بحيث يبحث المحلل عن الموضع التالي.
الانتقال إلى السلسلة الأخيرة
كما هو مذكور أعلاه، ولكن المحلل يبحث عن آخر ظهور للتعبير.
تدعم المعلمات التالية معالجة الأحداث وفقًا لمهمة سجل أحداث الوكيل ويمكنها تتبع ما يصل إلى 4 أحداث.
الحدث
تعيين eventX
يتم تعيين حدث عندما يتطابق سطر مع تعبير أو سلسلة معينة.
يمكن تكوين وتعيين ما يصل إلى 32 حدثًا.
إعادة تعيين eventX
يتم إعادة تعيين الحدث عندما يتطابق سطر لاحق مع تعبير معين.
يمكن تكوين وتعيين ما يصل إلى 32 حدث إعادة تعيين.
إعادة تعيين الحدث X بعد
يتم إعادة تعيين الحدث بعد انتهاء مهلة زمنية معينة (على سبيل المثال 10m = 10 دقائق).
يمكن تكوين وتعيين ما يصل إلى 32 مهلة.
يتم تقييم شرط إعادة التعيين فقط في وقت تشغيل المهمة. إذا تم تعيين حدث ولم يتم العثور على سلاسل جديدة مطابقة أثناء تنفيذ المهمة التالية، فسيتم إعادة تعيين الحدث عند الوصول إلى المهلة المذكورة أعلاه.
القيم
الحصول على القيمة X
يتم البحث عن قيمة رقمية بدءًا من الموضع الحالي وتعيينها إذا تم العثور عليها
وإلا يتم تعيين رمز الاستجابة على 8 (القيمة غير موجودة) ويتم إنهاء التنفيذ.
يتم تعيين مؤشر التحليل إلى الحرف الأول بعد القيمة التي تم العثور عليها. يؤدي
الضغط على زر الوحدة إلى ظهور مربع الحوار التالي: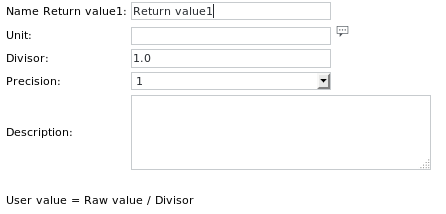
هنا يمكن تحديداسم القيمة المراد إرجاعها (اختياري)
وحدتها (على سبيل المثال، ثوانٍ، اختياري)
المقسوم الذي يجب تقسيم القيمة عليه (اختياري)
دقة الإخراج الرقمي (على سبيل المثال 1.000)
الحصول على قيمة الفرق X
بدءًا من الموضع الحالي، يتم البحث عن قيمة رقمية ويتم تعيين الفرق مع القيمة التي تم العثور عليها أثناء التنفيذ الأخير.
يتم تعيين مؤشر التحليل إلى الحرف الأول بعد القيمة التي تم العثور عليها.
الحصول على قيمة المعدل X
تمثل قيمة المعدل الفرق بين القيمة الحالية والقيمة الأخيرة مقسومة على مقدار الوقت (بالثواني) الذي مر بين القياسين:
(Valnow - Vallast) / (tnow - tlast)
عادةً ما يتم أخذ الطابع الزمني لتنفيذ المهمة لهذا الحساب. ومع ذلك، يمكن أيضًا قراءته من الملف باستخدام عنصر الحصول على الطابع الزمني (المعدل) (انظر أعلاه)
إذا كان فرق الطابع الزمني <= 0، فلن يتم إنشاء قيمة معدل جديدة.
الحصول على قيمة السلسلة X
يتيح هذا الحصول على قيمة سلسلة من ملف. استخدم هذا فقط للسلاسل التي لا تتغير كثيرًا، أي استخدمه عندما تكون السلسلة واحدة من عدد قليل من السلاسل المعروفة بأنها جزء من النص الذي تم تحليله.
يمكن تعيين السلسلة إلى قيمة رقمية باستخدام حقول التكوين التي يمكن الوصول إليها عند النقر فوق الزر وحدة.
مقارنة سلسلة
يتم تقييم التعبير (الذي قد يكون سلسلة بسيطة، ولكن يمكن أن يكون أيضًا تعبيرًا عاديًا) ويتم تعيين 1 (موجود) أو 0 (غير موجود) كقيمة مرتجعة.
يمكن التأثير على اسم قيمة الإرجاع أعلاه والنص الذي يظهر بجوار قيمة الإرجاع بالنقر فوق الزر Enum الموجود على يمين هذا المعلمة. يؤدي هذا إلى فتح مربع الحوار التالي:

والذي سيعرض ما يلي للمقارنة الناجحة في قسم القيم: حالة
التحقق: 1 (الحالة جيدة)
بدلاً من الإعداد الافتراضي:
مقارنة النتيجة 1: 1 (موجود)
وهذا يسمح بتعيين قيمة الإرجاع إلى رسالة معينة.يمكن استخدام الأحرف الخاصة ^ أو $ للبحث عن تعبيرات في بداية أو نهاية السطر. على سبيل المثال، سيؤدي إدخال "^AAA" (بدون علامات اقتباس) إلى إرجاع Found إذا كانت السلسلة "AAA" موجودة في بداية السطر، ولكنه سيعيد Not found إذا كان السطر يحتوي على أي شيء آخر غير "AAA" ولكنه يبدأ به. وبالمثل، سيؤدي إدخال "AAA$" إلى العثور على السلسلة فقط إذا كانت موجودة في نهاية السطر.
إذا تم إدخال مجموعة من مجموعات السلسلة/القيمة بالتنسيق "1=AAA، 2=BBB" أو "1=AAA،2=BBB،0=*" وتم العثور على سلسلة من المجموعة بعد الموضع الحالي في السطر الحالي، يتم تعيين الرقم المناسب كقيمة إخراج (يعرض المثال الثاني 0 للسلاسل غير الموجودة في المجموعة). وهذا يسمح بقيم إرجاع أكثر من القيمة الافتراضية 0 أو 1. بالإضافة إلى ذلك، يمكن بعد ذلك تعيين قيم الإرجاع هذه إلى رسائل الإخراج باستخدام حقل Enum.
يجب تجاوز الأحرف الخاصة التي عادةً ما تكون جزءًا من تعبير عادي، على سبيل المثال "("، باستخدام شرطة مائلة عكسية حتى يتم مطابقتها بشكل صحيح.
يتم تعيين مؤشر التحليل إلى الحرف الأول بعد التعبير الذي تم تقييمه والذي لا يكون فراغًا أو علامة جدولة أو شريطًا عموديًا (| أو ¦) أو إلى العمود التالي إذا تم تعريف فاصل.
عدد مطابقات السلسلة
إذا تم إصدار معلمة سطر في التسلسل أعلاه، يتم حساب جميع مرات ظهور السلسلة في السطر الحالي، وإلا يتم حساب جميع مرات ظهور السلسلة في الملف بأكمله.
لا يتم تحريك مؤشر التحليل.
نص إلى رسالة معلومات
يتم نسخ النص من موقع مؤشر التحليل الحالي إلى نهاية السطر إلى رسالة المعلومات. إذا لم يكن هناك نص، يتم تعيين رمز الاستجابة على 9 (لم يتم العثور على نص للمعلومات) ويتم إنهاء التنفيذ.
لا يتم تحريك مؤشر التحليل.
قيم ملف التحليل وحدود الإنذار
يمكن أن تدخل مهمة ملف التحليل حالات الصيانة "الصيانة على ما يرام" أو "صيانة كبيرة"، اعتمادًا على حدود الإنذار الأخرى التي تم تكوينها. على سبيل المثال، إذا تم تكوين حد الإنذار التالي:
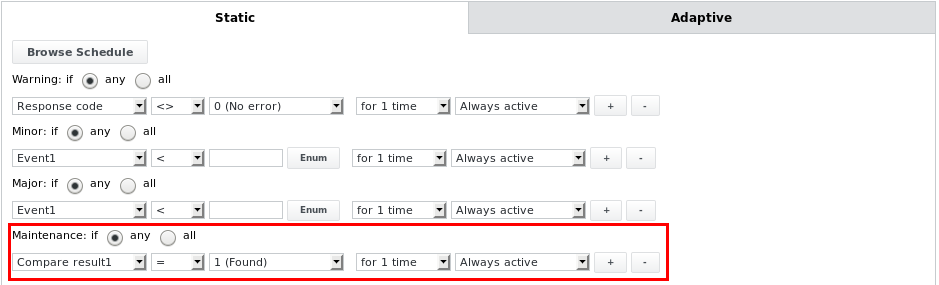
ستدخل المهمة حالة الصيانة جيدة إذا تطابق مقارنة النص مع سلسلة أو تعبير معين وإذا كانت في حالة جيدة. يمكن استخدام هذا لوضع المهمة وجهازها الأصلي (تنتقل الصيانة من المهمة إلى جهازها) في وضع الصيانة اعتمادًا على ما يتم العثور عليه عند تحليل ملف يحتوي على معلومات عن حالة الصيانة، على سبيل المثال من أنظمة مراقبة أخرى مثل Nagios. يمكن أيضًا استخدام جميع حدود الإنذار الأخرى أدناه في حد الإنذار الخاص بالصيانة.
القيمة / حد الإنذار | الوصف |
|---|---|
Event1-X | يتحقق مما إذا كان قد تم تشغيل حدث بناءً على معلمة تسلسل الحدث المحدد أعلاه. |
القيمة المرجعة 1-X | قيمة رقمية محددة من قبل المستخدم بناءً على معلمة تسلسل الحصول على القيمة أعلاه. |
قيمة المعدل 1-X | قيمة معدل رقمية محددة من قبل المستخدم بناءً على معلمة تسلسل الحصول على قيمة المعدل أعلاه. |
قيمة الفرق 1-X | قيمة فرق رقمية محددة من قبل المستخدم استنادًا إلى معلمة تسلسل الحصول على قيمة الفرق أعلاه. |
قيمة السلسلة 1-X | قيمة سلسلة محددة من قبل المستخدم استنادًا إلى معلمة تسلسل الحصول على قيمة السلسلة أعلاه. |
مقارنة النتيجة 1-X | قيمة محددة من قبل المستخدم بناءً على معلمة تسلسل قيمة السلسلة المقارنة أعلاه. |
عداد المطابقة 1-X | قيمة محددة من قبل المستخدم استنادًا إلى معلمة تسلسل عدد مطابقات السلسلة أعلاه. |
رمز الاستجابة | 0 لا يوجد |
رمز الخطأ | رمز خطأ عام في المهمة (انظر قسم رموز أخطاء المهام) |
أمثلة على تحليل الملف
مثال 1 - تحليل ملف file.txt الذي يحتوي على المحتوى التالي لقراءة القيم الثلاث في الأسطر الثلاثة الأخيرة:
11;OK;33;44.9888;MK;Duration (average): 203.6533s Open cases: 10 8 1
تبدو تكوينات المهمة كما يلي:
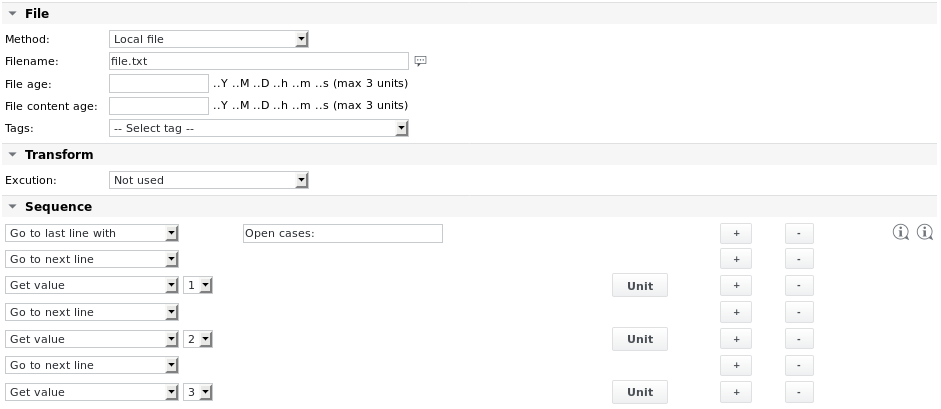
تعريف الوحدة للعنصر Get value الأول هو:
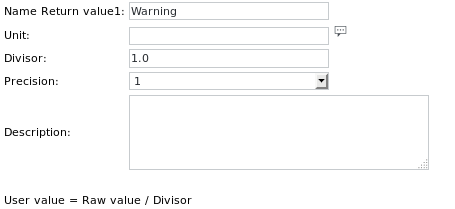
تعريفات الوحدتين الأخريين متشابهة وتسمى Minor و Major على التوالي.
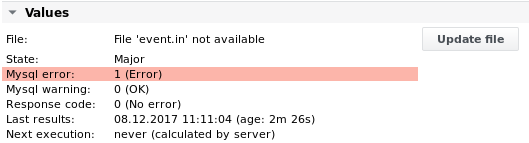
الإخراج 1
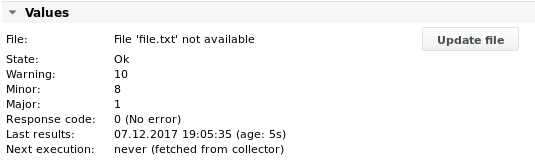
مثال 2 - تحليل نفس الملف file.txt واستخراج القيم من سطره الأول بناءً على الأعمدة
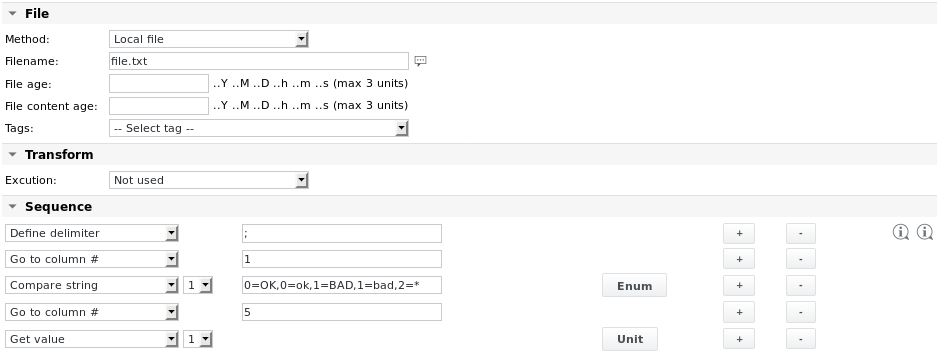
تعريف Enum لعنصر Compare string 1 هو:

النص الكامل: 0=الحالة جيدة، 1=الحالة ليست جيدة، 2=الحالة غير معروفة
تعريف الوحدة لـ Get value 1 هو:
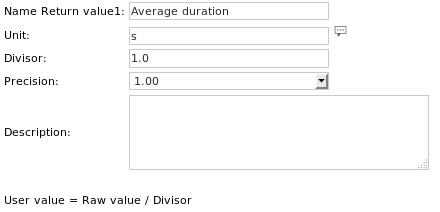
لاحظ زيادة الدقة، لتتمكن من قراءة القيم العددية ذات النقاط العائمة.
الإخراج 2
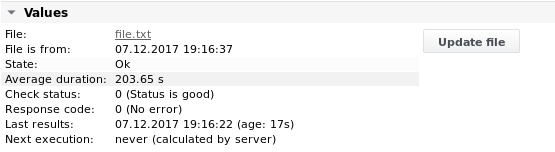
مثال 3 - ابحث عن سطر يحتوي على اسم الخادم باستخدام علامات متغيرة. ابق على هذا السطر واحصل على القيم MeasurementValue1 و CPU_Usage
محتويات الملف هي:
Timestamp=Fri Oct 31 09:55:20 CET 2017 ServerName=myserver01;MeasurementValue1=1.11;CPU_Usage=10%;EnumValue1=OK; ServerName=myserver02;MeasurementValue1=1.22;CPU_Usage=22%;EnumValue1=BAD;
اسم الجهاز هو myserver01.
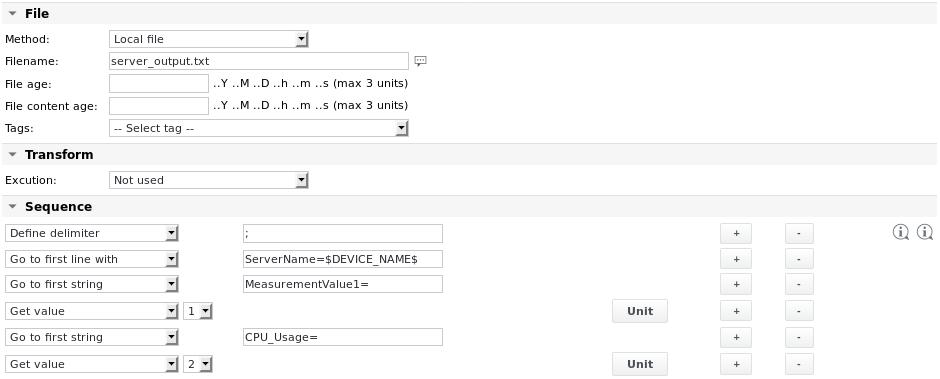
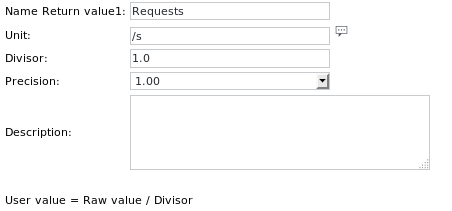
تعريفات الوحدة هي:
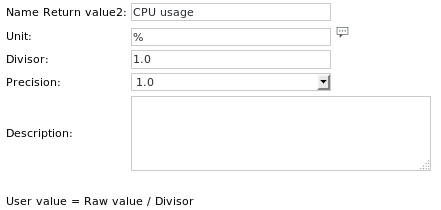
يتيح استخدام علامات محرك SKOOR نسخ المهام إلى أجهزة مختلفة مع استمرار عملها باستخدام اسم الجهاز الصحيح.
الإخراج 3
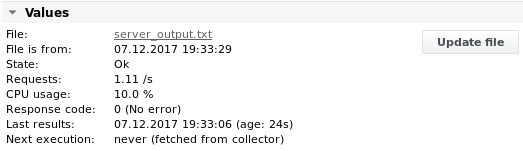
مثال 4 - قراءة طابع زمني من ملف يتم إنشاؤه بانتظام وقراءة قيمة المعدل للحصول على عدد الحزم الواردة والصادرة على واجهة الشبكة
يتم إنشاء الملف بانتظام بالمحتوى التالي من مهمة تنفيذ مع محتويات البرنامج النصي المضمن التالية:
date +%s%N | cut -c1-13 netstat -I=eth0
السطر الأول يطبع الطابع الزمني (بالثواني منذ 1.1.1970) بدقة الميلي ثانية، والسطر الثاني يطبع إحصائيات الاستقبال/الإرسال على واجهة الشبكة eth0. الملف الذي تم إنشاؤه هو:
1512726065120 Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 5761332 0 0 0 2932100 0 0 0 BMRU
قيم المعدل (الحزم الواردة والصادرة) مستقلة عن فترات تنفيذ كل من مهمة التنفيذ ومهمة parsefile. عادةً ما يتم وضع مهمة التنفيذ ومهمة parsefile أسفل مهمة Batch وتعيين فترة تنفيذ لهما بدون تكرار، وستكون مهمة Batch هي الوحيدة التي لها فترة تنفيذ.
تبدو مهمة parsefile كما يلي:
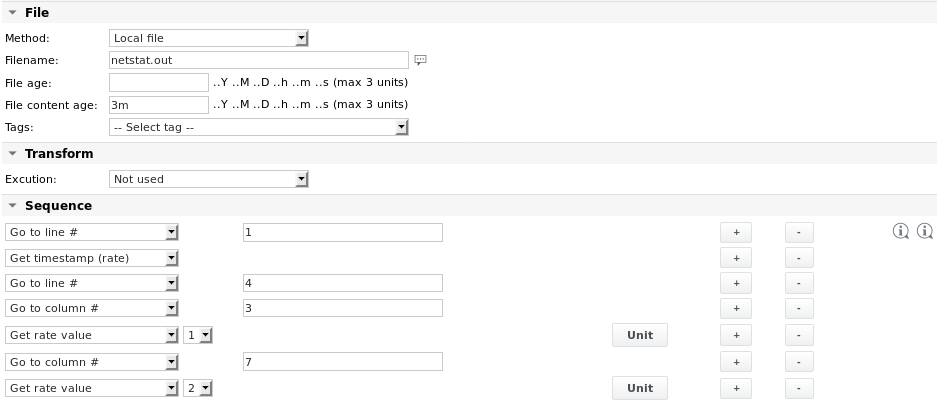
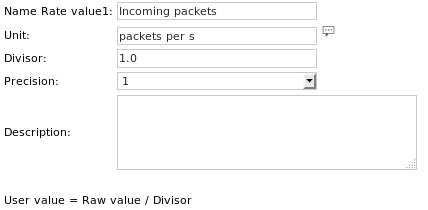
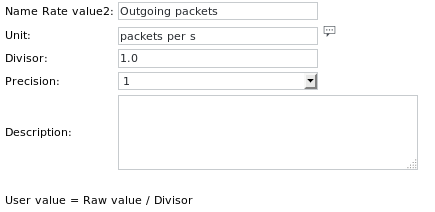
تعريفات الوحدة هي:
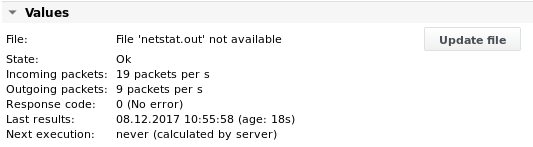
الإخراج 4
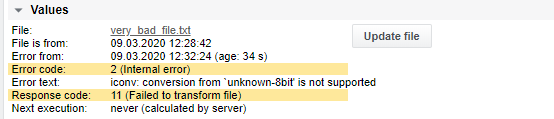
تُطبع القيم بعد التنفيذ الثاني للمهمة (تحتاج قيمة المعدل إلى مقارنة مع القياس السابق):
مثال 5 - إنشاء أحداث من المحتوى الذي تم تحليله
اقرأ ملفًا تم إنشاؤه من خلال مهمة خارجية وابحث عن سلاسل معينة. قم بإنشاء حدث 1 عند العثور على السلسلة Error. أعد تعيين الحدث بعد فترة زمنية معينة. قم أيضًا بإنشاء حدث 2 إذا تم العثور على السلسلة Process mysqld terminated. أعد تعيين الحدث الثاني فقط إذا تم العثور على السلسلة Process mysqld started في موضع لاحق في الملف أو أثناء تنفيذ المهمة التالية.
في هذا المثال، يقوم العنصر الأول في تسلسل التحليل بتعيين معلمة وضع Syslog. وهذا يضمن تحليل البيانات الجديدة فقط في الملف. لا يتم أخذ الأجزاء القديمة من الملف التي تم تحليلها أثناء تنفيذ المهمة الأخيرة في الاعتبار عند تنفيذ المهام اللاحقة. إذا عثرت المهمة الأولى على السلسلة Error في الملف، فإنها تحدد Event1. إذا لم يتم العثور على سلاسل Error جديدة أثناء تنفيذ المهام العشر التالية (تم تعيين الفاصل الزمني للمهمة على دقيقة واحدة)، يتم إعادة تعيين الحدث.
تسمح آلية الحدث للمهمة بالعودة إلى حالة OK بعد فترة زمنية معينة مع الاحتفاظ بإمكانية تشغيل بريد إلكتروني للتنبيه عند تعيين حدث.
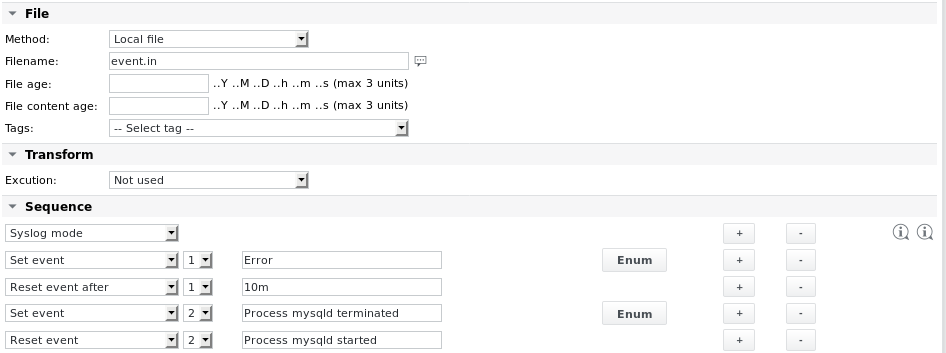
تعريفات Enum هي:


يتم تكوين حدود التنبيه على النحو التالي:
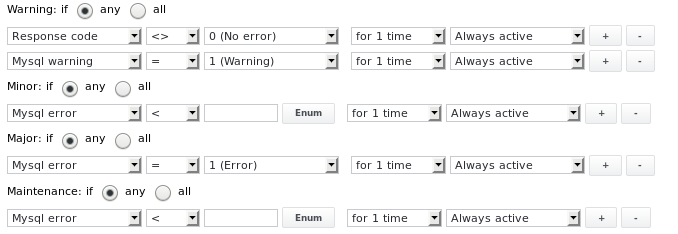
الإخراج 5