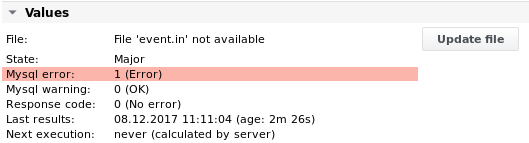
Parsefile
Fonction | Analyse un fichier à la recherche de texte et/ou de valeurs, génère des valeurs différentielles. Jusqu'à 32 valeurs / valeurs de chaîne / valeurs différentielles / valeurs de taux / résultats de comparaison / compteurs de correspondance et événements sont possibles par tâche d'analyse. |
|---|---|
Alarme | Correspondances de chaînes, nombre de chaînes, valeurs, valeurs de chaînes, valeurs différentielles, valeurs de taux, événements, âge du fichier, âge du contenu du fichier, code de réponse Particularité : la tâche peut passer à l'état Maintenance OK ou Maintenance Major, en fonction des limites d'alarme configurées. |
Détails du fichier d'analyse
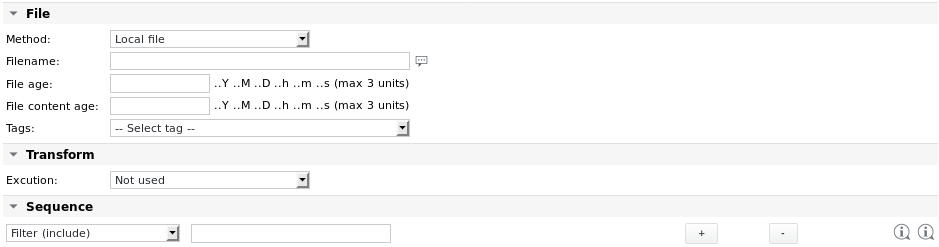
Paramètres du fichier d'analyse
Paramètre | Description |
|---|---|
Méthode | Le fichier à analyser peut être soit un fichier local (par défaut), soit un fichier récupéré au préalable à l'aide de l'un des protocoles suivants : HTTP Si l'un des protocoles distants est choisi, des paramètres supplémentaires s'affichent pour le chemin d'accès source et l'authentification utilisateur. Voir la tâche Fetchfile pour plus de détails sur la configuration. Exemple : récupérer d'abord le fichier à partir d'un serveur Web, avant de l'analyser : Il est préférable de récupérer un fichier distant à partir de la tâche Parsefile. Une alternative consiste à créer une tâche batch avec une tâche Fetchfile ou Agent Fetchfile et une tâche Parsefile. Si le système distant fonctionne sous Windows et que SKOOR WinAgent est installé, les fichiers peuvent également être récupérés à l'aide de WinAgent. WinAgent apparaît dans la liste déroulante des méthodes dès que les propriétés Nom d'utilisateur de l'agent et Mot de passe de l'agent sont définies sur le périphérique des tâches. Sous Windows 10, le serveur OpenSSH peut être installé à partir des fonctionnalités optionnelles. Après avoir démarré le service correspondant, les fichiers peuvent être copiés à l'aide de scp. |
Nom de fichier | Nom du fichier à analyser. Le chemin d'accès peut être spécifié par rapport au répertoire d'analyse par défaut sur le collecteur (défini dans le fichier /etc/opt/eranger/eranger-collecteur.cfg, normalement défini sur /var/opt/run/eranger/collecteur/tmp) ou absolu. Si le fichier se trouve dans un sous-répertoire du répertoire par défaut configuré, le nom du fichier peut être saisi comme suit : sous-répertoire/fichier.txt |
Âge du fichier | Teste la date et l'heure du dernier accès au fichier. S'il est plus ancien que la valeur indiquée, la tâche émet un Warning (Fichier trop ancien). L'âge du fichier peut être saisi en minutes ou en secondes, les formats tels que « 1h 30m » sont également pris en charge. |
Âge du contenu du fichier | Teste si le contenu du fichier a changé. S'il n'a pas changé pendant la durée saisie ici, la tâche émet un Warning (Contenu du fichier trop ancien). Le format de l'âge du contenu du fichier est le même que pour le paramètre Âge du fichier. |
Transformation → Exécution | Si la transformation automatique fournie par la tâche n'est pas suffisante pour une raison quelconque, le fichier peut être prétraité par l'une des options suivantes avant d'être analysé : Non utilisé (pas de prétraitement) |
Séquence | Voir la section suivante |
La liste déroulante Balises permet de saisir des variables prédéfinies dans les champs ci-dessus, par exemple $NAME$ pour le nom du travail.
Transformations de fichiers standard
Si un fichier a été récupéré à partir d'un système autre que Linux, certains caractères spéciaux doivent être adaptés pour l'analyse. La liste suivante indique les cas traités automatiquement par la tâche :
Les caractères de retour chariot Windows sont supprimés (ce qui était auparavant effectué par l'option de transformation dos2unix).
Si le fichier est encodé en UTF-8 avec BOM (Byte Order Mark), le BOM est supprimé
Si le fichier est encodé en unicode (UTF-16 big-endian ou UTF-16 little-endian)
Si aucune transformation n'est définie, le fichier est converti en UTF-8 avant l'analyse
Si une transformation est définie, aucune modification n'est apportée au fichier (on suppose que la transformation traite correctement le fichier)
En cas d'échec de la transformation, les codes de réponse et d'erreur de la tâche afficheront les messages suivants :
Le code de réponse 11 (Échec de la transformation du fichier) s'affiche toujours et doit être configuré comme limite d'alarme
Le code d'erreur 1 (erreur système) ou 2 (erreur interne) peut également s'afficher
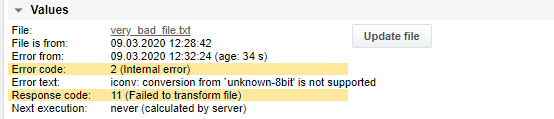
Séquence d'analyse du fichier
Comportement général
Si le fichier est introuvable, le code de réponse est défini sur 1 (Fichier introuvable) et l'exécution est interrompue.
Si l'âge du fichier et/ou l'âge du contenu du fichier sont définis, ces vérifications sont effectuées avant l'analyse du fichier.
Si le fichier est trop ancien, le code de réponse est défini sur 2 (Fichier trop ancien), mais le fichier est tout de même analysé.
Si le contenu du fichier est trop ancien, le code de réponse est défini sur 3 (Contenu du fichier trop ancien), mais le fichier est tout de même analysé.
Si un fichier contient plus de 100 000 lignes, le code de réponse est défini sur 4 (Fichier trop long) et l'exécution est interrompue. La limite par défaut peut être augmentée ou supprimée en ajoutant la ligne suivante dans le fichier de configuration du SKOOR Engine /opt/eranger/etc/eranger-collector.cfg :
parsefile_line_limit = 1000000 raise limit to a million lines parsefile_line_limit = 0 remove limit altogether
Lors de l'ajout de nouvelles valeurs, de valeurs de chaîne, de valeurs Diff, etc., un maximum de 32 entrées est possible dans la séquence d'analyse pour chaque type de valeur. Par exemple, lorsque vous ajoutez 3 valeurs à l'aide de l'élément Get value, commencez par ajouter Get value avec l'index 1, puis 2, puis 3, en augmentant le nombre d'index. L'interface utilisateur permet uniquement de sélectionner un index maximal en fonction du nombre d'éléments de séquence actuellement configurés, afin que la liste déroulante de sélection d'index ne prenne pas trop de place.
Éléments disponibles dans la liste déroulante du filtre de séquence
Définir
Filtrer (inclure)
Toutes les lignes du fichier qui ne contiennent pas l'expression sont ignorées. Par exemple, si vous entrez « localhost » (sans guillemets), seules les lignes contenant « localhost » seront prises en compte ; les autres lignes seront ignorées.
Filtrer (exclure)
Cela fonctionne à l'inverse, c'est-à-dire comme un filtre négatif.
Toutes les lignes contenant l'expression sont ignorées pour l'analyse du reste de la séquence.
Définir le délimiteur
Le délimiteur de colonne par défaut est l'espace (1 espace, plusieurs espaces consécutifs, tabulations). Cela divise efficacement les lignes en mots.
Un autre délimiteur peut être choisi ici. Entrez une chaîne d'un ou plusieurs caractères, comme « ; » ou « COL ». Au cours d'une séquence, le délimiteur peut être défini et réinitialisé plusieurs fois. Pour le réinitialiser, laissez le champ de texte vide.
Le nombre de colonnes commence à 0 (zéro).
Mode Syslog
Si cette option est activée, l'analyse se poursuit avec la première nouvelle ligne ajoutée au fichier depuis la dernière exécution de la tâche.
Si le fichier a été roté, le fichier roté est utilisé à partir de la dernière position EOF afin qu'aucune donnée ne soit perdue.
Ignorer la casse
Si cette option est activée, la casse est ignorée pour les comparaisons de chaînes.
Ignorer les éléments introuvables
Si une ligne, une expression ou une colonne est introuvable, le code de réponse n'est pas défini sur 7 Chaîne introuvable, mais l'exécution de la tâche est interrompue.
Continuer après non trouvé
Si cette option est activée, l'analyse se poursuit après qu'une ligne ou une colonne n'a pas été trouvée.
Détecter le dépassement de capacité activé/désactivé
Si cette option est activée, tous les paramètres de valeur Diff suivants dans la séquence ignoreront les valeurs inférieures à la valeur mesurée lors de l'exécution précédente du travail (seules les différences positives sont autorisées).
Cette option est principalement utilisée pour les compteurs. Le paramètre peut être désactivé plus tard dans la séquence.
Obtenir l'horodatage (taux)
Un horodatage peut être lu à partir d'un fichier pour des calculs exacts à l'aide du paramètre de séquence Obtenir la valeur du taux. Par exemple, si le fichier analysé est généré par une application exécutée de manière asynchrone.
L'horodatage dans le fichier doit être imprimé en secondes, en millisecondes ou en microsecondes.
Rechercher
Les paramètres suivants se réfèrent aux lignes. La portée du paramètre suivant est la ligne trouvée par le paramètre actuel. Si une ligne demandée n'existe pas, le code de réponse est défini sur 5 (Ligne introuvable) et l'exécution est terminée, sauf si Continuer après introuvable est défini.Aller à la ligne n°
Le pointeur d'analyse est positionné au début de la ligne correspondante.
Aller à la ligne suivante
Le pointeur d'analyse est positionné au début de la ligne suivante.
Aller à la première ligne avec
Le pointeur d'analyse est positionné au début de la première ligne qui évalue la chaîne/expression.
Si aucune ligne contenant une telle expression n'est trouvée et que l'option « Continuer après non trouvé » est activée, le pointeur d'analyse est positionné au premier caractère de la première ligne du fichier et le reste de la séquence est traité.
Aller à la ligne suivante avec
Le pointeur d'analyse est positionné au début de la ligne suivante qui évalue la chaîne/expression.
Si aucune ligne contenant une telle expression n'est trouvée et que l'option « Continuer après non trouvé » est activée, le pointeur d'analyse est positionné sur le premier caractère de la ligne suivante et le reste de la séquence est traité.
Aller à la dernière ligne avec
Le pointeur d'analyse est positionné au début de la dernière ligne qui évalue la chaîne/expression.
Si aucune ligne contenant une telle expression n'est trouvée et que l'option « Continuer après non trouvé » est activée, le pointeur d'analyse est positionné sur le premier caractère de la première ligne du fichier et le reste de la séquence est traité.
Rechercher le délimiteur
Les commandes suivantes dépendent de la définition d'un délimiteur. Si aucun délimiteur n'est défini, les espaces (espaces ou tabulations) sont utilisés comme délimiteurs.Aller à la colonne n°
Le pointeur d'analyse est positionné sur le premier caractère de la colonne correspondante (0..n) dans la ligne actuelle.
Si la colonne n'est pas trouvée, le code de réponse est défini sur 6 (Colonne introuvable) et l'exécution est terminée.
Si la colonne est introuvable et que l'option Continuer après introuvable est activée, la position du pointeur d'analyse n'est pas modifiée.
La portée des commandes de chaîne suivantes est par défaut l'ensemble du fichier ; si l'une des commandes de ligne a été appelée précédemment, la portée est la ligne actuelle.
Si le champ est laissé vide, le code d'erreur est défini sur 7 (Paramètre non valide) et l'exécution est interrompue.
Aller à la première chaîne
En fonction de la portée, la première occurrence de la chaîne dans l'ensemble du fichier / dans la ligne actuelle qui évalue l'expression est recherchée.
Si elle est trouvée, le pointeur d'analyse est positionné sur le premier caractère qui évalue l'expression, puis incrémenté de la longueur de l'expression.
Sinon, l'exécution est interrompue et le code de réponse est défini sur 7 (chaîne introuvable), sauf si Ignorer introuvable ou Continuer après introuvable a été défini ci-dessus.
Aller à la chaîne suivante
Comme ci-dessus, mais la recherche commence à la position actuelle afin que l'analyseur recherche la prochaine occurrence.
Aller à la dernière chaîne
Comme ci-dessus, mais l'analyseur recherche la dernière occurrence d'une expression.
Les paramètres suivants prennent en charge la gestion des événements conformément à la tâche Agent Eventlog et peuvent suivre jusqu'à 4 événements.
Événement
Définir l'événement X
Un événement est défini lorsqu'une ligne correspond à une expression ou une chaîne donnée.
Il est possible de configurer et de définir jusqu'à 32 événements.
Réinitialiser l'événement X
Un événement est réinitialisé lorsqu'une ligne suivante correspond à une expression donnée.
Il est possible de configurer et de définir jusqu'à 32 événements de réinitialisation.
Réinitialiser l'événement X après
Un événement est réinitialisé après un délai d'attente donné (par exemple, 10 m = 10 minutes).
Il est possible de configurer et de définir jusqu'à 32 délais d'attente.
La condition de réinitialisation est évaluée uniquement au moment de l'exécution de la tâche. Si un événement a été défini et qu'aucune nouvelle chaîne correspondante n'est trouvée lors de la prochaine exécution de la tâche, l'événement sera réinitialisé si le délai d'attente ci-dessus est atteint.
Valeurs
Obtenir la valeur X
À partir de la position actuelle, une valeur numérique est recherchée et attribuée si elle est trouvée.
Sinon, le code de réponse est défini sur 8 (valeur introuvable) et l'exécution est interrompue.
Le pointeur d'analyse est défini sur le premier caractère après la valeur trouvée.
Appuyez sur le bouton Unité pour afficher la boîte de dialogue suivante :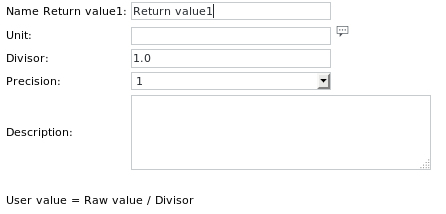
Ici, vous pouvez spécifierle nom de la valeur à renvoyer (facultatif)
son unité (par exemple, secondes, facultatif)
un diviseur par lequel la valeur doit être divisée (facultatif)
la précision de la sortie numérique (par exemple 1,000)
Obtenir la valeur diffX
À partir de la position actuelle, une valeur numérique est recherchée et la différence par rapport à la valeur trouvée lors de la dernière exécution est attribuée.
Le pointeur d'analyse est défini sur le premier caractère après la valeur trouvée.
Obtenir la valeur du tauxX
La valeur du taux représente la différence entre la valeur actuelle et la dernière valeur divisée par le temps (en secondes) écoulé entre les deux mesures :
(Valnow - Vallast) / (tnow - tlast)
En général, l'horodatage de l'exécution de la tâche est utilisé pour ce calcul. Il peut toutefois également être lu à partir du fichier à l'aide de l'élément Obtenir l'horodatage (taux) (voir ci-dessus).
Si la différence d'horodatage est <= 0, aucune nouvelle valeur de taux n'est générée.
Obtenir la valeur de la chaîne
Cela permet de recevoir une valeur de chaîne à partir d'un fichier. Utilisez cette fonction uniquement pour les chaînes qui ne changent pas souvent, c'est-à-dire lorsque la chaîne fait partie des quelques chaînes connues pour faire partie du texte analysé.
La chaîne peut être mappée à une valeur numérique à l'aide des champs de configuration accessibles en cliquant sur le bouton Unité.
Comparer la chaîneX
L'expression (qui peut être une simple chaîne, mais aussi une expression régulière) est évaluée et la valeur de retour attribuée est soit 1 (Trouvé), soit 0 (Non trouvé).
Le nom de la valeur de retour ci-dessus et le texte qui s'affiche à côté de la valeur de retour peuvent être modifiés en cliquant sur le bouton Enum à droite de ce paramètre. Cela ouvre la boîte de dialogue suivante :

qui affichera les éléments suivants pour une comparaison réussie dans la section Valeurs :
Vérifier l'état : 1 (État OK)
au lieu de la valeur par défaut :
Comparer le résultat 1 : 1 (Trouvé)
Cela permet de mapper la valeur de retour à un message spécifique.Les caractères spéciaux ^ ou $ peuvent être utilisés pour rechercher des expressions au début ou à la fin d'une ligne. Par exemple, la saisie de « ^AAA » (sans guillemets) renverra Trouvé si la chaîne « AAA » se trouve au début de la ligne, mais renverra Non trouvé si la ligne contient autre chose que « AAA » au début. De même, la saisie de « AAA$ » ne trouvera la chaîne que si elle se trouve à la fin de la ligne.
Si un ensemble de combinaisons chaîne/valeur au format « 1=AAA, 2=BBB » ou « 1=AAA,2=BBB,0=* » est saisi et qu'une chaîne de l'ensemble est trouvée après la position actuelle sur la ligne actuelle, le nombre approprié est attribué comme valeur de sortie (le deuxième exemple renvoie 0 pour les chaînes qui ne font pas partie de l'ensemble). Cela permet d'obtenir plus de valeurs de retour que la valeur par défaut 0 ou 1. De plus, ces valeurs de retour peuvent ensuite être mappées à des messages de sortie à l'aide du champ Enum.
Les caractères spéciaux qui font généralement partie d'une expression régulière, par exemple « ( », doivent être échappés avec une barre oblique inversée pour être correctement mis en correspondance.
Le pointeur d'analyse est défini sur le premier caractère après l'expression évaluée qui n'est pas un espace, une tabulation ou une barre verticale (| ou ¦) ou sur la colonne suivante si un délimiteur a été défini.
Compter les correspondances de chaîneX
Si un paramètre de ligne a été émis dans la séquence ci-dessus, toutes les occurrences d'une chaîne dans la ligne actuelle sont comptées, sinon toutes les occurrences de la chaîne dans l'ensemble du fichier sont comptées.
Le pointeur d'analyse n'est pas déplacé.
Texte du message d'information
Le texte situé entre l'emplacement actuel du pointeur d'analyse et la fin de la ligne est copié dans le message d'information. S'il n'y a pas de texte, le code de réponse est défini sur 9 (Texte pour info introuvable) et l'exécution est terminée.
Le pointeur d'analyse n'est pas déplacé.
Valeurs du fichier d'analyse et limites d'alarme
La tâche parsefile peut entrer dans les états de maintenance Maintenance OK ou Maintenance Major, en fonction des autres limites d'alarme configurées. Par exemple, si la limite d'alarme suivante est configurée :
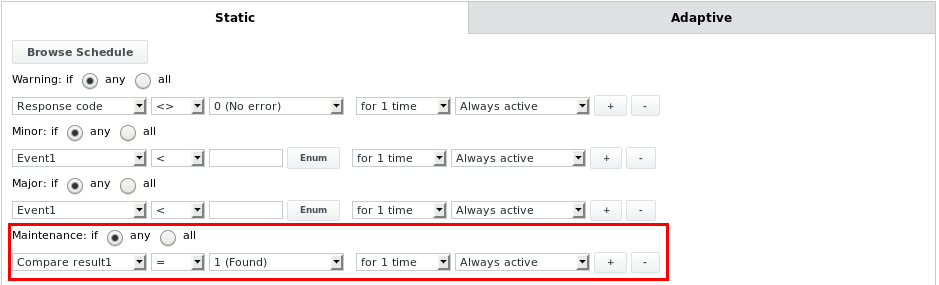
La tâche passera à l'état Maintenance OK si la comparaison de texte correspond à une chaîne ou une expression donnée et si elle est par ailleurs dans l'état OK. Cela peut être utilisé pour mettre la tâche et son périphérique parent (la maintenance est propagée vers le haut depuis une tâche vers son périphérique) en mode maintenance en fonction de ce qui est trouvé lors de l'analyse d'un fichier contenant des informations sur l'état de maintenance, par exemple à partir d'autres systèmes de surveillance tels que Nagios. Toutes les autres limites d'alarme ci-dessous peuvent également être utilisées dans la limite d'alarme Maintenance.
Valeur / Limite d'alarme | Description |
|---|---|
Événement1-X | Vérifie si un événement a été déclenché en fonction du paramètre Séquence d'événements définis ci-dessus. |
Valeur de retour1-X | Valeur numérique définie par l'utilisateur en fonction du paramètre de séquence Obtenir la valeur ci-dessus. |
Valeur de taux 1-X | Valeur numérique définie par l'utilisateur en fonction du paramètre de séquence Get rate value ci-dessus. |
Diff value1-X | Valeur numérique de différence définie par l'utilisateur en fonction du paramètre de séquence Obtenir la valeur de différence ci-dessus. |
Valeur de chaîne 1-X | Valeur de chaîne définie par l'utilisateur en fonction du paramètre de séquence Obtenir la valeur de chaîne ci-dessus. |
Résultat de comparaison 1-X | Valeur définie par l'utilisateur basée sur le paramètre de séquence Comparer la valeur de la chaîne ci-dessus. |
Compteur de correspondances1-X | Valeur définie par l'utilisateur basée sur le paramètre de séquence Compter les correspondances de chaîne ci-dessus. |
Code de réponse | 0 Aucune |
Code d'erreur | Code d'erreur générique de la tâche (voir la section Codes d'erreur des tâches) |
Exemples d'analyse de fichiers
Exemple 1 - Analyser un fichier file.txt dont le contenu est le suivant afin de lire les 3 valeurs des 3 dernières lignes :
11;OK;33;44.9888;MK;Duration (average): 203.6533s Open cases: 10 8 1
La configuration de la tâche se présente comme suit :
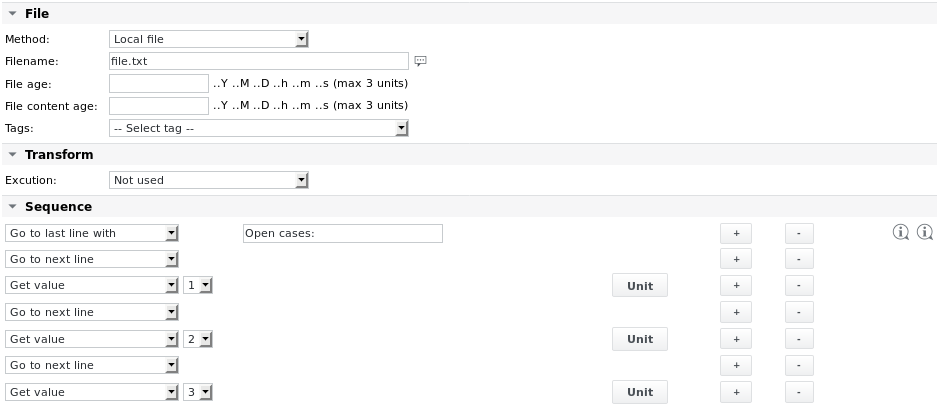
La définition de l'unité du premier élément Get value est la suivante :
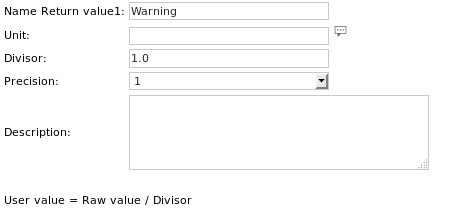
Les deux autres définitions d'unité sont similaires et portent respectivement les noms Minor et Major.
Sortie 1
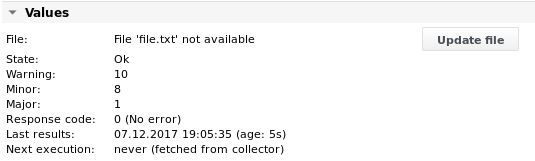
Exemple 2 - Analyser le même fichier file.txt et extraire les valeurs de sa première ligne en fonction des colonnes
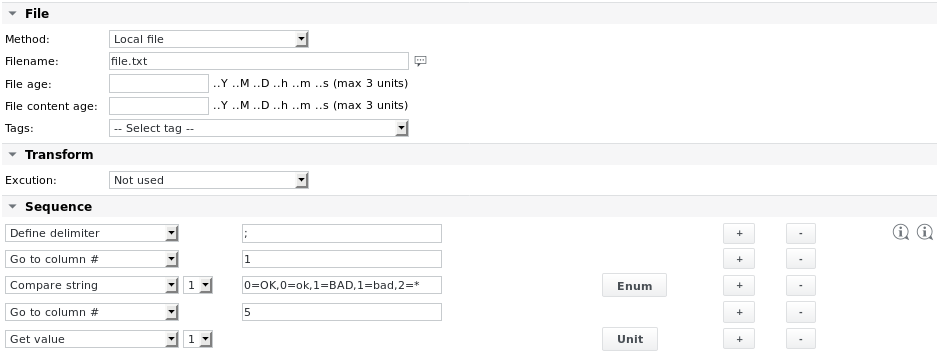
La définition Enum de l'élément Compare string 1 est la suivante :

Texte complet : 0=Statut correct, 1=Statut moins bon, 2=Statut inconnu
La définition de l'unité pour Get value 1 est la suivante :
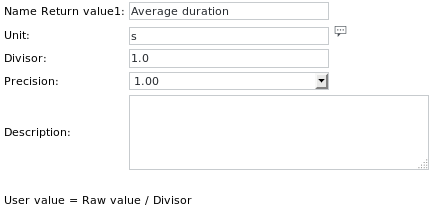
Notez l'augmentation de la précision, afin de pouvoir lire les valeurs numériques à virgule flottante.
Sortie 2
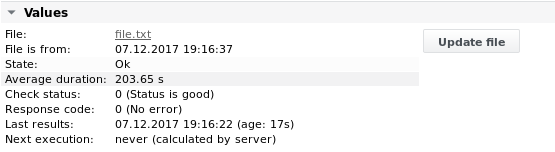
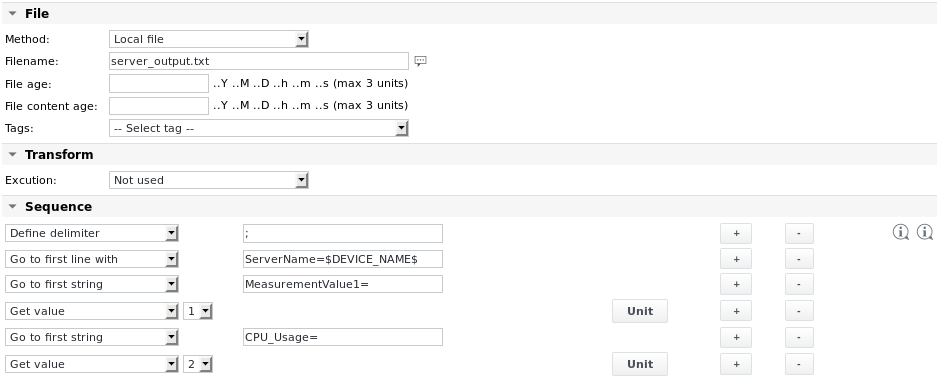
Exemple 3 - Recherchez une ligne contenant le nom du server à l'aide de balises variables. Restez sur cette ligne et récupérez les valeurs MeasurementValue1 et CPU_Usage
Le contenu du fichier est le suivant :
Timestamp=Fri Oct 31 09:55:20 CET 2017 ServerName=myserver01;MeasurementValue1=1.11;CPU_Usage=10%;EnumValue1=OK; ServerName=myserver02;MeasurementValue1=1.22;CPU_Usage=22%;EnumValue1=BAD;
Le nom du périphérique est myserver01.
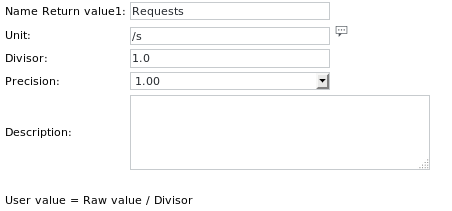
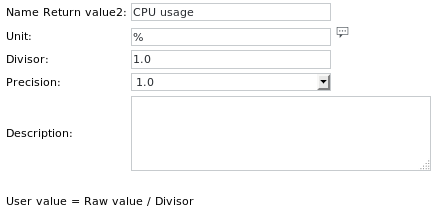
Les définitions des unités sont les suivantes :
L'utilisation des balises SKOOR Engine permet de copier des tâches vers différents périphériques tout en continuant à les faire fonctionner avec le nom de périphérique correct.
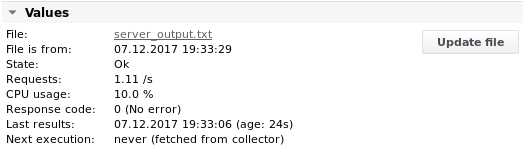
Sortie 3
Exemple 4 - Lire un horodatage à partir d'un fichier généré régulièrement et lire la valeur du débit pour obtenir le nombre de paquets entrants et sortants sur une interface réseau
Le fichier est généré régulièrement avec le contenu suivant à partir d'une tâche Execute avec le contenu du script Inline suivant :
date +%s%N | cut -c1-13 netstat -I=eth0
La première ligne affiche l'horodatage (en secondes depuis le 1.1.1970) avec une précision de l'ordre de la milliseconde, la deuxième ligne affiche les statistiques de réception/transmission sur l'interface réseau eth0. Le fichier généré est le suivant :
1512726065120 Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 5761332 0 0 0 2932100 0 0 0 BMRU
Les valeurs de débit (paquets entrants et sortants) sont indépendantes des intervalles d'exécution de la tâche d'exécution et de la tâche parsefile. En général, on place la tâche d'exécution et la tâche parse sous une tâche Batch et on leur attribue un intervalle d'exécution « Aucune répétition », et seule la tâche Batch a un intervalle d'exécution.
La tâche parsefile se présente comme suit :
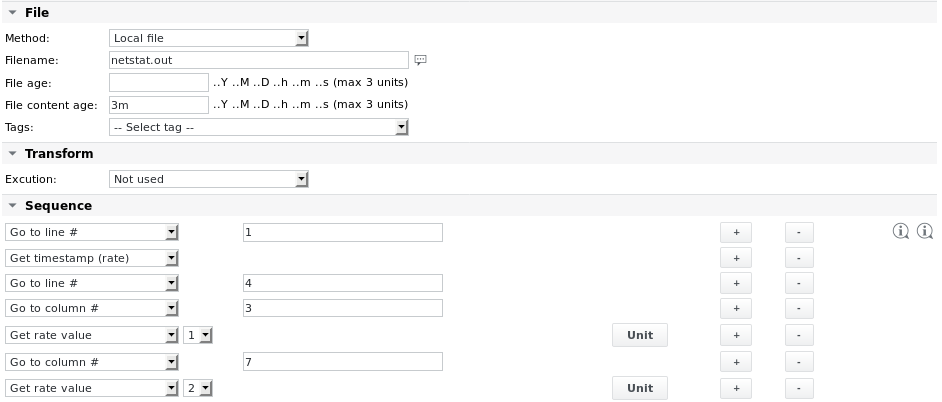
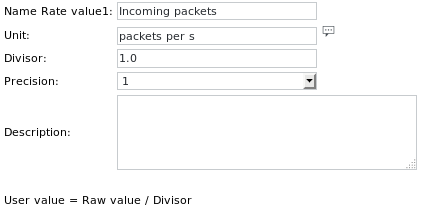
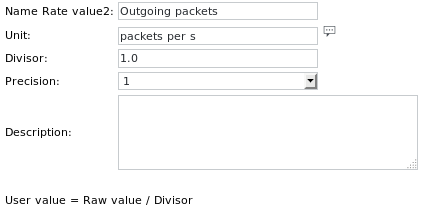
Les définitions des unités sont les suivantes :
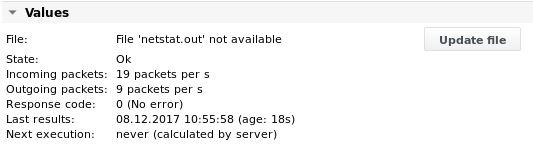
Sortie 4
Les valeurs sont imprimées après la deuxième exécution de la tâche (la valeur du débit doit être comparée à la mesure précédente) :
Exemple 5 - Générer des événements à partir du contenu analysé
Lisez un fichier généré par une tâche externe et recherchez certaines chaînes. Générez un événement1 lorsque la chaîne Error est trouvée. Réinitialisez l'événement après un certain temps. Générez également un événement2 si la chaîne Process mysqld terminated est trouvée. Réinitialisez le deuxième événement uniquement si la chaîne Process mysqld started est trouvée plus loin dans le fichier ou lors de la prochaine exécution de la tâche.
Dans cet exemple, le premier élément de la séquence d'analyse définit le paramètre Syslog mode. Cela garantit que seules les nouvelles données du fichier sont analysées. Les parties plus anciennes du fichier qui ont été analysées lors de la dernière exécution de la tâche ne sont plus prises en compte pour les exécutions suivantes. Si la première exécution de la tâche trouve la chaîne Error dans le fichier, elle définit l'événement 1. Si aucune nouvelle chaîne Error n'est trouvée au cours des 10 exécutions suivantes de la tâche (l'intervalle de la tâche est défini sur 1 minute), l'événement est réinitialisé.
Le mécanisme d'événement permet au travail de revenir à un état OK après un certain temps tout en conservant la possibilité de déclencher un e-mail d'alarme lorsqu'un événement est défini.
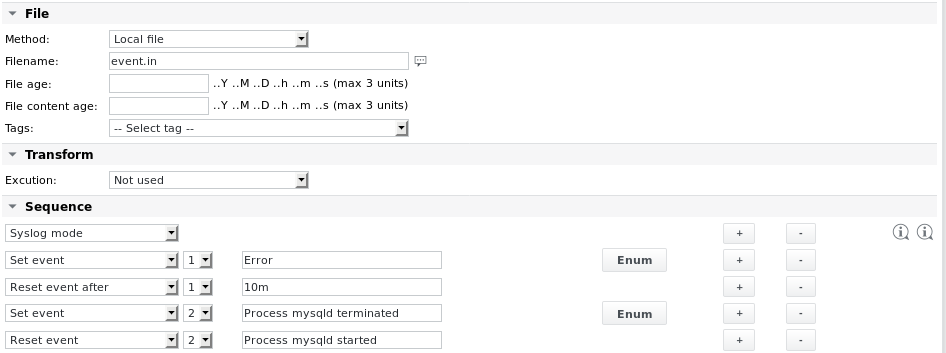
Les définitions Enum sont les suivantes :


Les limites d'alarme sont configurées comme suit :
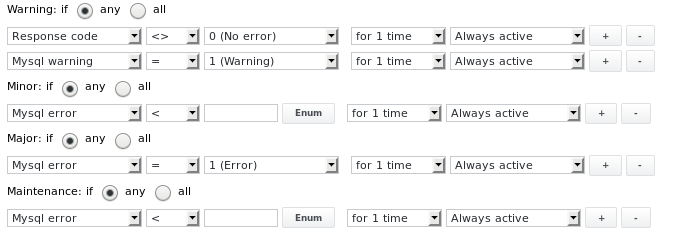
Sortie 5