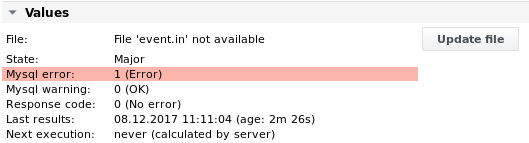
Parsefile
Funzione | Analizza un file alla ricerca di testo e/o valori, crea valori differenziali. Per ogni operazione di analisi sono possibili fino a 32 valori / valori stringa / valori diff / valori di tasso / risultati di confronto / contatori di corrispondenza ed eventi. |
|---|---|
Allarme | Corrispondenze stringa, conteggi stringa, valori, valori stringa, valori differenziali, valori di tasso, eventi, età file, età contenuto file, codice risposta Speciale: il lavoro può entrare nello stato Maintenance OK o Maintenance Major, in base ai limiti di allarme configurati. |
Dettagli del file di analisi
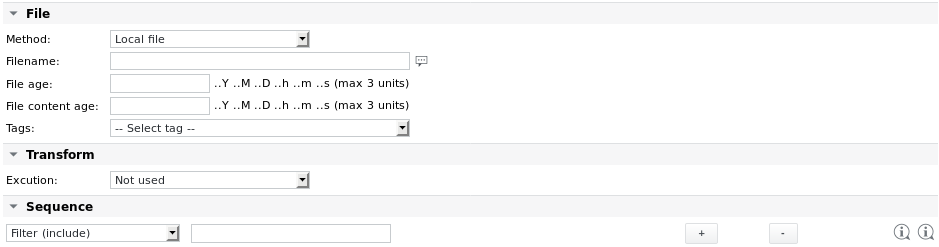
Parametri del file di analisi
Parametro | Descrizione |
|---|---|
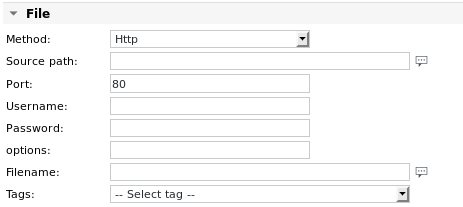
Metodo | Il file da analizzare può essere un file locale (impostazione predefinita) oppure può essere recuperato utilizzando uno dei seguenti protocolli: HTTP Se si sceglie uno dei protocolli remoti, vengono visualizzati parametri aggiuntivi per il percorso di origine e l'autenticazione dell'utente. Per i dettagli sulla configurazione, vedere il lavoro Fetchfile. Esempio: recuperare prima il file da un server web, prima di analizzarlo: Il modo migliore per recuperare un file remoto è dall'interno del lavoro Parsefile. Un'alternativa sarebbe quella di creare un lavoro batch con un lavoro Fetchfile o Agent Fetchfile e un lavoro Parsefile. Se il sistema remoto è in esecuzione su Windows e SKOOR WinAgent è installato, i file possono essere recuperati anche utilizzando WinAgent. WinAgent è elencato nel menu a discesa dei metodi, non appena le proprietà Nome utente agente e Password agente sono impostate sul dispositivo dei lavori. Su Windows 10, il server OpenSSH può essere installato dalle funzionalità opzionali. Dopo aver avviato il servizio corrispondente, i file possono essere copiati utilizzando scp. |
Nome file | Il nome del file da analizzare. Il percorso può essere specificato in relazione alla directory di analisi predefinita sul collettore (definita nel file /etc/opt/eranger/eranger-collector.cfg, normalmente impostata su /var/opt/run/eranger/collector/tmp) o in modo assoluto. Se il file si trova in una sottodirectory della directory predefinita configurata, il nome del file può essere inserito come: subdir/file.txt |
Età del file | Verifica la data e l'ora dell'ultimo accesso al file. Se è più vecchio del valore specificato, il processo emette un Warning (File troppo vecchio). L'età del file può essere inserita in minuti o secondi, sono supportati anche formati come "1h 30m". |
Età del contenuto del file | Verifica se il contenuto del file è stato modificato. Se non è stato modificato durante il periodo specificato, il processo emette un Warning (Contenuto del file troppo vecchio). Il formato dell'età del contenuto del file è lo stesso del parametro Età del file. |
Trasformazione → Esecuzione | Se la trasformazione automatica fornita dal processo non è sufficiente per qualche motivo, il file può essere pre-elaborato con una delle seguenti opzioni prima di essere analizzato: Non utilizzato (nessuna pre-elaborazione) |
Sequenza | Vedere la sezione successiva |
L'elenco a discesa Tag consente di inserire variabili predefinite nei campi sopra indicati, ad esempio $NAME$ per il nome del lavoro.
Trasformazioni standard dei file
Se un file è stato recuperato da un sistema diverso da Linux, alcuni caratteri speciali devono essere adattati per l'analisi. Il seguente elenco mostra quali casi vengono gestiti automaticamente dal lavoro:
I caratteri di ritorno a capo di Windows vengono rimossi (precedentemente eseguito dall'opzione di trasformazione dos2unix)
Se il file è codificato in UTF-8 con BOM (Byte Order Mark), il BOM viene rimosso
Se il file è codificato in unicode (UTF-16 big-endian o UTF-16 little-endian)
Se non è definita alcuna trasformazione, il file viene convertito in UTF-8 prima dell'analisi
Se è definita una trasformazione, non viene eseguita alcuna operazione sul file (si presume che la trasformazione gestisca correttamente il file)
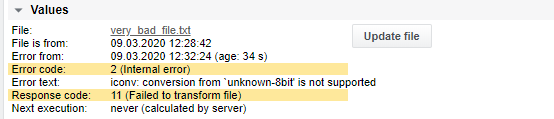
In caso di errore della trasformazione, i codici di risposta e di errore del processo visualizzeranno i seguenti messaggi:
Il codice di risposta 11 (Impossibile trasformare il file) verrà sempre visualizzato e dovrà essere configurato come limite di allarme
Il codice di errore 1 (Errore di sistema) o 2 (Errore interno) può essere visualizzato in aggiunta
Sequenza di analisi del file
Comportamento generale
Se il file non viene trovato, il codice di risposta viene impostato su 1 (File non trovato) e l'esecuzione viene terminata.
Se sono definiti l'età del file e/o l'età del contenuto del file, questi controlli vengono eseguiti prima dell'analisi del file.
Se il file è troppo vecchio, il codice di risposta viene impostato su 2 (File troppo vecchio), tuttavia il file viene comunque analizzato.
Se il contenuto del file è troppo vecchio, il codice di risposta viene impostato su 3 (Contenuto del file troppo vecchio), ma il file viene comunque analizzato.
Se un file contiene più di 100.000 righe, il codice di risposta viene impostato su 4 (File troppo lungo) e l'esecuzione viene interrotta. Il limite predefinito può essere aumentato o rimosso aggiungendo la seguente riga nel file di configurazione SKOOR Engine /opt/eranger/etc/eranger-collector.cfg:
parsefile_line_limit = 1000000 raise limit to a million lines parsefile_line_limit = 0 remove limit altogether
Quando si aggiungono nuovi valori, valori stringa, valori Diff ecc., è possibile inserire un massimo di 32 voci nella sequenza di analisi per ogni tipo di valore. Ad esempio, quando si aggiungono 3 valori utilizzando la voce Ottieni valore, iniziare aggiungendo Ottieni valore con indice 1, poi 2, poi 3, con un conteggio dell'indice crescente. L'interfaccia utente consente solo di selezionare un indice massimo in base al numero di elementi della sequenza attualmente configurati, in modo che l'elenco a discesa di selezione dell'indice non occupi troppo spazio.
Elementi disponibili nell'elenco a discesa del filtro della sequenza
Imposta
Filtro (includi)
Tutte le righe del file che non contengono l'espressione vengono ignorate, ad esempio inserendo "localhost" (senza virgolette) verranno considerate solo le righe contenenti "localhost"; le altre righe vengono ignorate.
Filtro (escludi)
Funziona al contrario, ovvero come filtro negativo.
Tutte le righe che contengono l'espressione vengono ignorate per l'analisi del resto della sequenza.
Definisci delimitatore
Il delimitatore di colonna predefinito è lo spazio bianco (1 spazio, più spazi consecutivi, tabulazioni). Questo divide efficacemente le righe in parole.
Qui è possibile scegliere un delimitatore diverso. Inserire una stringa di 1 o più caratteri come ";" o "COL". Durante una sequenza, il delimitatore può essere impostato e reimpostato più volte. Per reimpostarlo, lasciare vuoto il campo di testo.
Il conteggio delle colonne inizia da 0 (zero).
Modalità syslog
Se questa opzione è impostata, l'analisi continua con la prima nuova riga aggiunta al file dall'ultima esecuzione del processo.
Se il file è stato ruotato, viene utilizzato il file ruotato dall'ultima posizione EOF in modo che non vengano persi dati.
Ignora maiuscole/minuscole
Se questa opzione è impostata, le maiuscole/minuscole vengono ignorate nei confronti tra stringhe.
Ignora non trovato
Se una riga, un'espressione o una colonna non viene trovata, il codice di risposta non viene impostato su 7 String not found (Stringa non trovata), ma l'esecuzione del processo viene terminata.
Continua dopo non trovato
Se questa opzione è impostata, l'analisi continua anche se una riga o una colonna non viene trovata.
Rileva overflow on/off
Se questa opzione è abilitata, tutti i parametri del valore Diff che seguono nella sequenza ignoreranno i valori inferiori al valore misurato nell'esecuzione precedente del processo (sono consentite solo differenze positive).
Questa opzione viene utilizzata principalmente per i contatori. L'impostazione può essere disattivata più avanti nella sequenza.
Ottieni timestamp (frequenza)
È possibile leggere un timestamp da un file per calcoli esatti utilizzando il parametro di sequenza Ottieni valore di frequenza. Ad esempio, se il file analizzato è generato da un'applicazione eseguita in modo asincrono.
Il timestamp nel file deve essere stampato in unità di secondi, ms o µs.
Trova
I seguenti parametri si riferiscono alle righe. L'ambito del parametro successivo è la riga trovata dal parametro corrente. Se una riga richiesta non esiste, il codice di risposta viene impostato su 5 (Riga non trovata) e l'esecuzione viene terminata, tranne se è impostato Continua dopo non trovato.Vai alla riga #
Il puntatore di analisi viene posizionato all'inizio della riga corrispondente.
Vai alla riga successiva
Il puntatore di analisi è posizionato all'inizio della riga successiva.
Vai alla prima riga con
Il puntatore di analisi è posizionato all'inizio della prima riga che valuta la stringa/espressione.
Se non è possibile trovare una riga con tale espressione e l'opzione "Continua dopo non trovato" è impostata, il puntatore di analisi viene posizionato sul primo carattere della prima riga del file e viene elaborata la parte restante della sequenza.
Vai alla riga successiva con
Il puntatore di analisi viene posizionato all'inizio della riga successiva che valuta la stringa/espressione.
Se non è possibile trovare una riga con tale espressione e l'opzione "Continua dopo non trovato" è impostata, il puntatore di analisi viene posizionato sul primo carattere della riga successiva e viene elaborata la parte restante della sequenza.
Vai all'ultima riga con
Il puntatore di analisi viene posizionato all'inizio dell'ultima riga che valuta la stringa/espressione.
Se non è possibile trovare una riga con tale espressione e l'opzione "Continua dopo non trovato" è impostata, il puntatore di analisi viene posizionato sul primo carattere della prima riga del file e viene elaborata la parte restante della sequenza.
Trova delimitatore basato
I seguenti comandi dipendono dalla definizione di un delimitatore. Se non è definito alcun delimitatore, come delimitatore viene utilizzato lo spazio bianco (spazi o tabulazioni).Vai alla colonna #
Il puntatore di analisi viene posizionato sul primo carattere della colonna corrispondente (0..n) nella riga corrente.
Se la colonna non viene trovata, il codice di risposta viene impostato su 6 (Colonna non trovata) e l'esecuzione viene terminata.
Se la colonna non viene trovata e l'opzione Continua dopo mancata individuazione è impostata, la posizione del puntatore di analisi non viene modificata.
L'ambito dei seguenti comandi stringa è impostato di default sull'intero file; se uno dei comandi di riga è stato chiamato in precedenza, l'ambito è la riga corrente.
Se il campo viene lasciato vuoto, il codice di errore viene impostato su 7 (Parametro non valido) e l'esecuzione viene terminata.
Vai alla prima stringa
A seconda dell'ambito, viene cercata la prima occorrenza della stringa nell'intero file / nella riga corrente che valuta l'espressione.
Se trovata, il puntatore di analisi viene posizionato sul primo carattere che valuta l'espressione e quindi incrementato della lunghezza dell'espressione
Altrimenti l'esecuzione viene terminata e il codice di risposta viene impostato su 7 (Stringa non trovata), tranne se sopra è stato impostato Ignora se non trovato o Continua dopo non trovato.
Vai alla stringa successiva
Come sopra, ma la ricerca inizia dalla posizione corrente, quindi il parser cercherà la successiva occorrenza.
Vai all'ultima stringa
Come sopra, ma il parser cerca l'ultima occorrenza di un'espressione.
I seguenti parametri supportano la gestione degli eventi in base al processo Agent Eventlog e possono tracciare fino a 4 eventi.
Evento
Imposta eventoX
Un evento viene impostato quando una riga corrisponde a una determinata espressione o stringa.
È possibile configurare e impostare fino a 32 eventi.
Reimposta eventoX
Un evento viene ripristinato quando una riga successiva corrisponde a una determinata espressione.
È possibile configurare e impostare fino a 32 eventi di ripristino.
Reimposta eventoX dopo
Un evento viene ripristinato dopo un determinato timeout (ad esempio 10m = 10 minuti).
È possibile configurare e impostare fino a 32 timeout.
La condizione di ripristino viene valutata solo durante l'esecuzione del processo. Se è stato impostato un evento e non vengono trovate nuove stringhe corrispondenti durante la successiva esecuzione del processo, l'evento verrà ripristinato al raggiungimento del timeout sopra indicato.
Valori
Ottieni valoreX
A partire dalla posizione corrente, viene cercato un valore numerico e, se trovato, viene assegnato.
Altrimenti il codice di risposta viene impostato su 8 (Valore non trovato) e l'esecuzione viene terminata.
Il puntatore di analisi viene impostato sul primo carattere dopo il valore trovato.
Premendo il pulsante Unità viene visualizzata la seguente finestra di dialogo: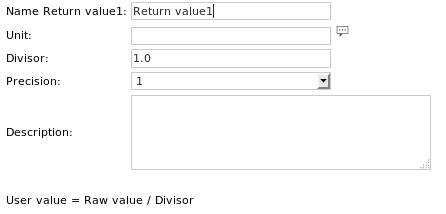
Qui è possibile specificareil nome del valore da restituire (facoltativo)
la sua unità (ad es. secondi, facoltativo)
un divisore per cui il valore deve essere diviso (facoltativo)
la precisione dell'output numerico (ad es. 1.000)
Ottieni valore diffX
A partire dalla posizione corrente viene cercato un valore numerico e viene assegnata la differenza rispetto al valore trovato durante l'ultima esecuzione.
Il puntatore di analisi viene impostato sul primo carattere dopo il valore trovato.
Ottieni valore tassoX
Il valore del tasso rappresenta la differenza tra il valore corrente e l'ultimo valore diviso per il tempo (in secondi) trascorso tra le due misurazioni:
(Valnow - Vallast) / (tnow - tlast)
Di solito per questo calcolo viene utilizzato il timestamp dell'esecuzione del lavoro. Tuttavia, è anche possibile leggerlo dal file utilizzando la voce Ottieni timestamp (tasso) (vedi sopra).
Se la differenza tra i timestamp è <= 0, non viene generato alcun nuovo valore di tasso.
Ottieni valore stringaX
Consente di ricevere un valore stringa da un file. Utilizzarlo solo per stringhe che non cambiano spesso, ovvero quando la stringa è una delle poche stringhe note che fanno parte del testo analizzato.
La stringa può essere mappata su un valore numerico utilizzando i campi di configurazione accessibili facendo clic sul pulsante Unità.
Confronta stringaX
L'espressione (che può essere una stringa semplice, ma anche un'espressione regolare) viene valutata e come valore di ritorno viene assegnato 1 (Trovato) o 0 (Non trovato).
Il nome del valore di ritorno sopra indicato e il testo visualizzato accanto al valore di ritorno possono essere modificati facendo clic sul pulsante Enum a destra di questo parametro. Si aprirà la seguente finestra di dialogo:

che mostrerà quanto segue per un confronto riuscito nella sezione Valori:
Controlla stato: 1 (Stato OK)
invece del valore predefinito:
Confronta risultato1: 1 (Trovato)
Ciò consente di mappare il valore restituito a un messaggio specifico.I caratteri speciali ^ o $ possono essere utilizzati per cercare espressioni all'inizio o alla fine di una riga. Ad esempio, inserendo "^AAA" (senza virgolette) verrà restituito Trovato se la stringa "AAA" si trova all'inizio della riga, tuttavia verrà restituito Non trovato se la riga contiene ma inizia con qualcosa di diverso da "AAA". Allo stesso modo, inserendo "AAA$" la stringa verrà trovata solo se si trova alla fine della riga.
Se viene immessa una serie di combinazioni stringa/valore nel formato "1=AAA, 2=BBB" o "1=AAA,2=BBB,0=*" e una stringa della serie viene trovata dopo la posizione corrente sulla riga corrente, il numero appropriato viene assegnato come valore di output (il secondo esempio restituisce 0 per le stringhe non presenti nella serie). Ciò consente di ottenere più valori di ritorno rispetto al valore predefinito 0 o 1. Inoltre, questi valori di ritorno possono essere ulteriormente mappati ai messaggi di output utilizzando il campo Enum.
I caratteri speciali che di solito fanno parte di un'espressione regolare, ad esempio "(", devono essere preceduti da una barra rovesciata per essere abbinati correttamente.
Il puntatore di analisi è impostato sul primo carattere dopo l'espressione valutata che non è uno spazio, un tabulatore o una barra verticale (| o ¦) o sulla colonna successiva se è stato definito un delimitatore.
Conta le corrispondenze della stringaX
Se è stato emesso un parametro di riga nella sequenza sopra indicata, vengono contate tutte le occorrenze di una stringa nella riga corrente, altrimenti vengono contate tutte le occorrenze della stringa nell'intero file.
Il puntatore di analisi non viene spostato.
Testo del messaggio informativo
Il testo dalla posizione corrente del puntatore di analisi alla fine della riga viene copiato nel messaggio informativo. Se non c'è testo, il codice di risposta viene impostato su 9 (Testo per informazioni non trovato) e l'esecuzione viene terminata.
Il puntatore di analisi non viene spostato.
Valori del file di analisi e limiti di allarme
Il processo di analisi del file può entrare negli stati di manutenzione Maintenance OK o Maintenance Major, a seconda degli altri limiti di allarme configurati. Ad esempio, se è configurato il seguente limite di allarme:
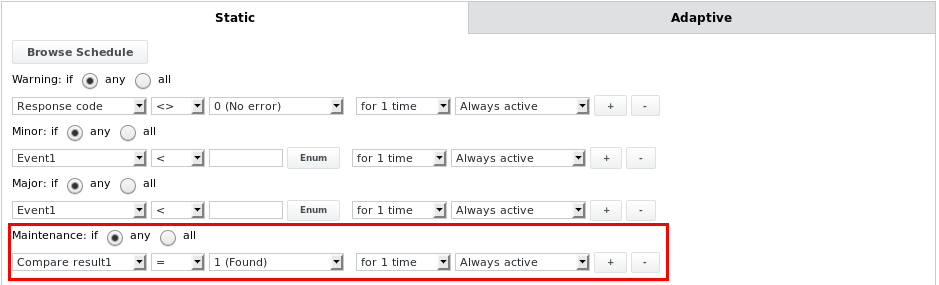
Il lavoro entrerà nello stato Maintenance OK se il confronto del testo corrisponde a una determinata stringa o espressione e se altrimenti si trova nello stato OK. Questo può essere utilizzato per mettere il lavoro e il suo dispositivo padre (la manutenzione viene propagata verso l'alto da un lavoro al suo dispositivo) in modalità di manutenzione a seconda di ciò che viene trovato durante l'analisi di un file che contiene informazioni sullo stato di manutenzione, ad esempio da altri sistemi di monitoraggio come Nagios. Tutti gli altri limiti di allarme riportati di seguito possono essere utilizzati anche nel limite di allarme Manutenzione.
Valore / Limite di allarme | Descrizione |
|---|---|
Evento1-X | Verifica se un evento è stato attivato in base al parametro Sequenza evento impostato sopra. |
Valore restituito1-X | Valore numerico definito dall'utente in base al parametro di sequenza Ottieni valore sopra indicato. |
Valore tasso1-X | Valore numerico definito dall'utente in base al parametro di sequenza Ottieni valore tasso sopra indicato. |
Valore diff1-X | Valore numerico della differenza definito dall'utente in base al parametro di sequenza Ottieni valore della differenza sopra indicato. |
Valore stringa1-X | Valore stringa definito dall'utente in base al parametro di sequenza Ottieni valore stringa sopra indicato. |
Risultato del confronto1-X | Valore definito dall'utente basato sul parametro di sequenza Confronta valore stringa sopra indicato. |
Contatore corrispondenze1-X | Valore definito dall'utente basato sul parametro di sequenza Conta corrispondenze stringa sopra indicato. |
Codice di risposta | 0 Nessun |
Codice di errore | Codice di errore generico del lavoro (vedere la sezione Codici di errore del lavoro) |
Esempi di analisi di file
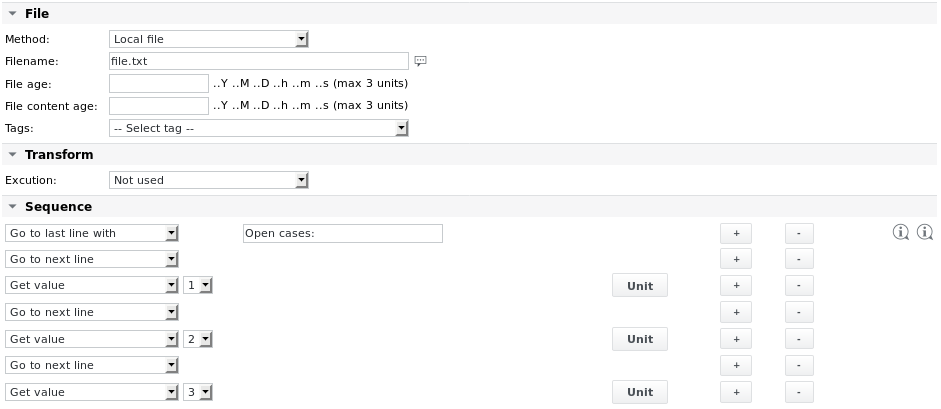
Esempio 1 - Analizza un file file.txt con il seguente contenuto per leggere i 3 valori nelle ultime 3 righe:
11;OK;33;44.9888;MK;Duration (average): 203.6533s Open cases: 10 8 1
La configurazione del lavoro è la seguente:
La definizione dell'unità del primo elemento Get value è:
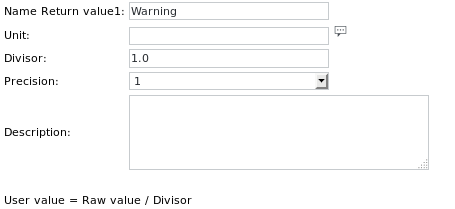
Le altre 2 definizioni dell'unità sono simili e hanno rispettivamente i nomi Minor e Major.
Output 1
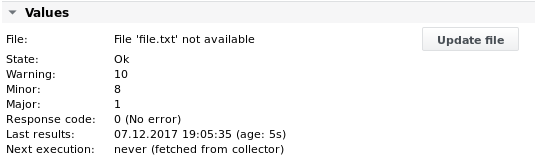
Esempio 2 - Analizzare lo stesso file.txt ed estrarre i valori dalla sua prima riga in base alle colonne
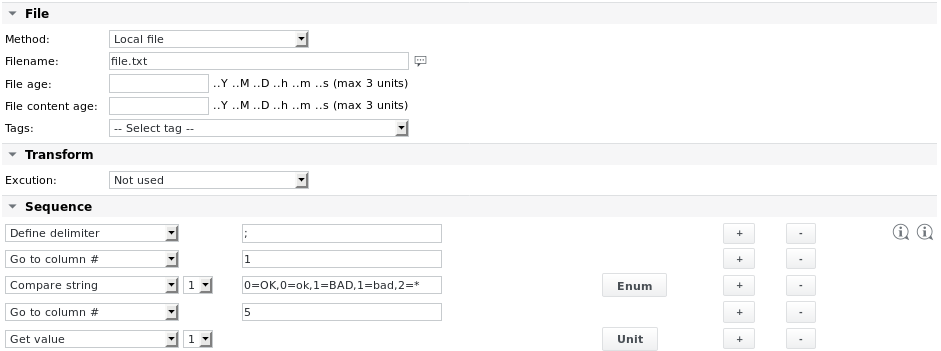
La definizione Enum dell'elemento Compare string 1 recita:

Testo completo: 0=Stato buono, 1=Stato non così buono, 2=Stato sconosciuto
La definizione dell'unità per Get value 1 recita:
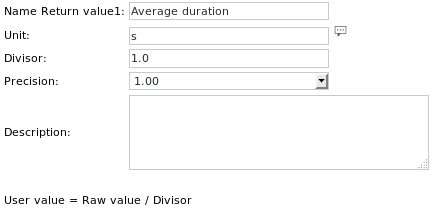
Notare l'aumento della precisione, per poter leggere valori numerici in virgola mobile.
Output 2
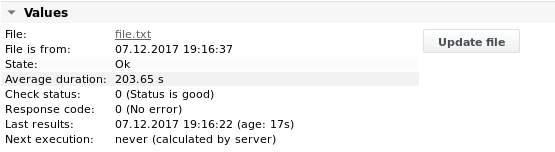
Esempio 3 - Ricerca di una riga contenente il nome del server utilizzando tag variabili. Rimanere su quella riga e ottenere i valori MeasurementValue1 e CPU_Usage
Il contenuto del file è:
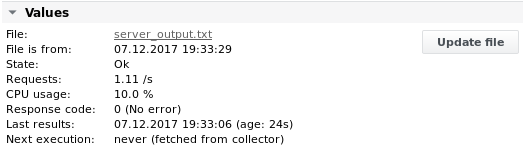
Timestamp=Fri Oct 31 09:55:20 CET 2017 ServerName=myserver01;MeasurementValue1=1.11;CPU_Usage=10%;EnumValue1=OK; ServerName=myserver02;MeasurementValue1=1.22;CPU_Usage=22%;EnumValue1=BAD;
Il nome del dispositivo è myserver01.
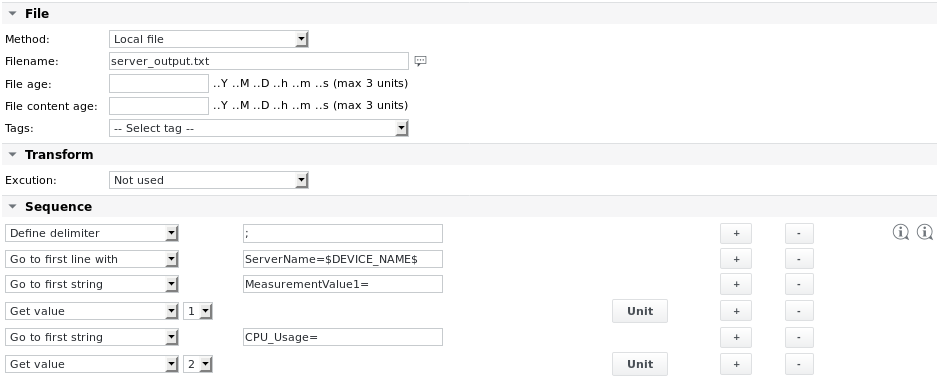
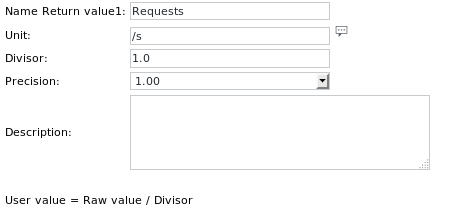
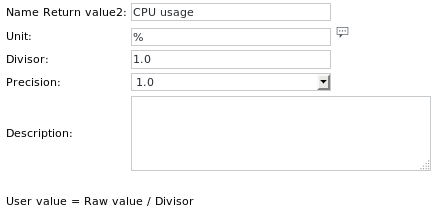
Le definizioni delle unità sono:
L'uso dei tag SKOOR Engine consente di copiare i lavori su dispositivi diversi e di farli funzionare comunque utilizzando il nome corretto del dispositivo.
Output 3
Esempio 4 - Leggere un timestamp da un file generato regolarmente e leggere il valore della velocità per ottenere il numero di pacchetti in entrata e in uscita su un'interfaccia di rete
Il file viene generato regolarmente con il seguente contenuto da un processo di esecuzione con il seguente contenuto dello script inline:
date +%s%N | cut -c1-13 netstat -I=eth0
La prima riga stampa il timestamp (secondi dal 1.1.1970) con precisione al millisecondo, la seconda riga stampa le statistiche di ricezione/trasmissione sull'interfaccia di rete eth0. Il file generato è:
1512726065120 Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 5761332 0 0 0 2932100 0 0 0 BMRU
I valori di velocità (pacchetti in entrata e in uscita) sono indipendenti dagli intervalli di esecuzione sia del processo di esecuzione che del processo di analisi del file. Di solito si inseriscono il processo di esecuzione e il processo di analisi sotto un processo batch e si assegna loro un intervallo di esecuzione senza ripetizione, e solo il processo batch avrà un intervallo di esecuzione.
Il lavoro di analisi del file ha il seguente aspetto:
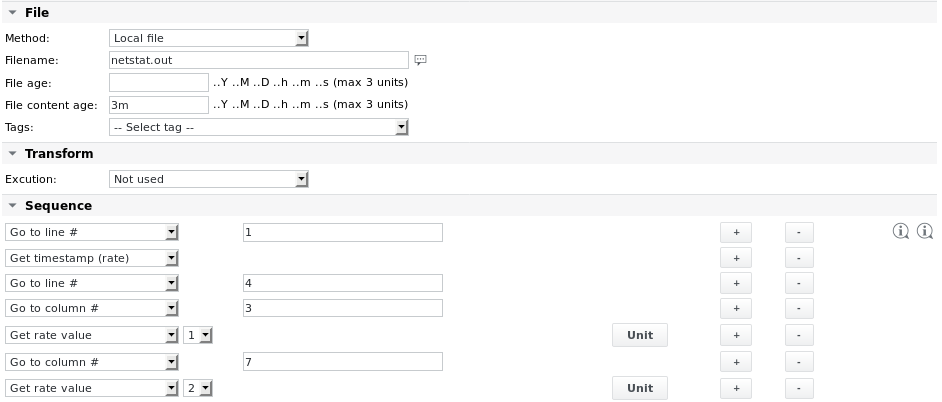
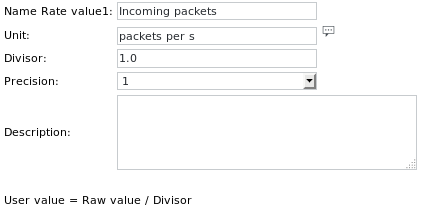
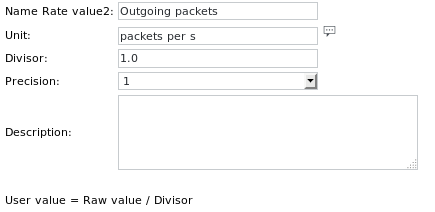
Le definizioni dell'unità sono:
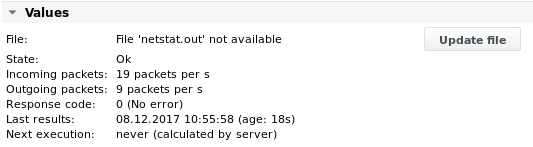
Output 4
I valori vengono stampati dopo la seconda esecuzione del lavoro (il valore della velocità richiede un confronto con la misurazione precedente):
Esempio 5 - Generare eventi dal contenuto analizzato
Leggi un file generato tramite un processo esterno e cerca determinate stringhe. Genera un evento1 quando viene trovata la stringa Error. Reimposta l'evento dopo un certo periodo di tempo. Genera anche un evento2 se viene trovata la stringa Process mysqld terminated. Reimposta il secondo evento solo se la stringa Process mysqld started viene trovata più avanti nel file o durante la successiva esecuzione del processo.
In questo esempio, il primo elemento nella sequenza di analisi imposta il parametro Syslog mode. Ciò garantisce che vengano analizzati solo i nuovi dati presenti nel file. Le parti più vecchie del file che sono state analizzate durante l'ultima esecuzione del processo non vengono più prese in considerazione per le esecuzioni successive. Se la prima esecuzione del processo trova la stringa Error nel file, imposta l'evento 1. Se non vengono trovate nuove stringhe Error durante le successive 10 esecuzioni del processo (l'intervallo di esecuzione è impostato su 1 minuto), l'evento viene reimpostato.
Il meccanismo degli eventi consente al processo di tornare allo stato OK dopo un certo periodo di tempo, pur mantenendo la possibilità di attivare un'e-mail di allarme quando viene impostato un evento.
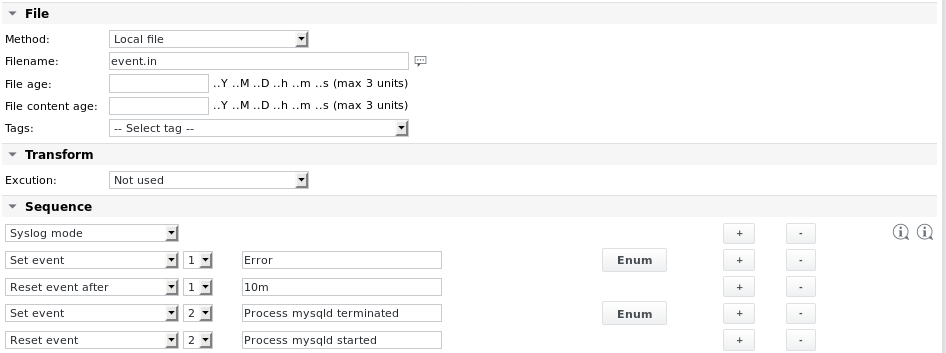
Le definizioni Enum sono:


I limiti di allarme sono configurati come segue:
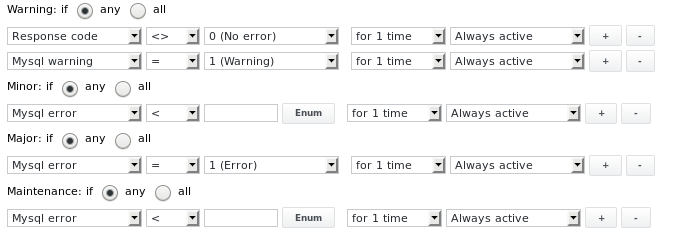
Uscita 5