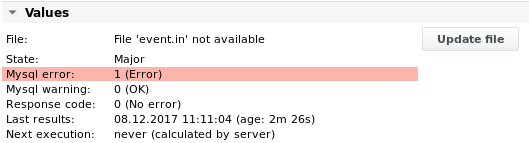
Parsefile
Funktion | Eine Datei nach Text und/oder Werten durchsuchen, Differenzwerte erstellen. Pro Durchsuchungsauftrag sind bis zu 32 Werte/Zeichenfolgenwerte/Differenzwerte/Ratenwerte/Vergleichsergebnisse/Übereinstimmungszähler und Ereignisse möglich. |
|---|---|
Alarmierung | Zeichenfolgenübereinstimmungen, Zeichenfolgenanzahl, Werte, Zeichenfolgenwerte, Differenzwerte, Ratenwerte, Ereignisse, Dateialter, Alter des Dateiinhalts, Antwortcode Besonderheit: Der Auftrag kann basierend auf konfigurierten Alarm Limits in den Status „Maintenance OK” oder „Maintenance Major” versetzt werden. |
Details zur Parsedatei
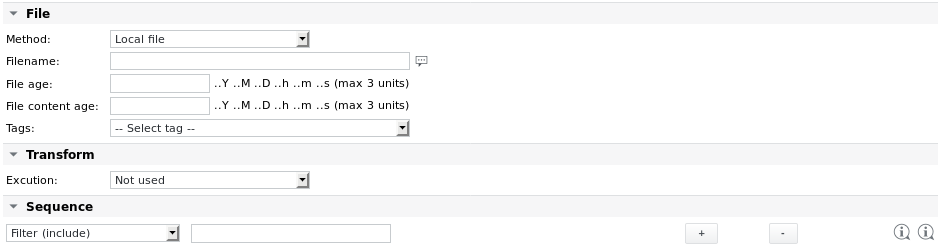
Parameter der zu analysierenden Datei
Parameter | Beschreibung |
|---|---|
Methode | Die zu parsende Datei kann entweder eine lokale Datei (Standard) sein oder zunächst über eines der folgenden Protokolle abgerufen werden: HTTP Wenn eines der Remote-Protokolle ausgewählt wird, werden zusätzliche Parameter für den Quellpfad und die Benutzerauthentifizierung angezeigt. Weitere Informationen zur Konfiguration finden Sie unter „Fetchfile-Job“. Beispiel: Datei zuerst von einem Webserver abrufen, bevor sie analysiert wird: Das Abrufen einer Remote-Datei aus dem Parsefile-Job ist die bevorzugte Methode. Eine Alternative wäre die Erstellung eines Batch-Jobs mit einem Fetchfile- oder Agent Fetchfile-Job und einem Parsefile-Job. Wenn das Remote-System unter Windows läuft und SKOOR WinAgent installiert ist, können Dateien auch mit WinAgent abgerufen werden. WinAgent wird in der Dropdown-Liste der Methoden aufgeführt, sobald die Eigenschaften „Agent-Benutzername” und „Agent-Passwort” auf dem Job-Gerät festgelegt sind. Unter Windows 10 kann der OpenSSH-Server aus den optionalen Funktionen installiert werden. Nach dem Start des entsprechenden Dienstes können Dateien mit scp kopiert werden. |
Dateiname | Der zu parsende Dateiname. Der Pfad kann relativ zum Standard-Parse-Verzeichnis auf dem Kollektor (definiert in der Datei /etc/opt/eranger/eranger-collector.cfg, normalerweise auf /var/opt/run/eranger/collector/tmp gesetzt) oder absolut angegeben werden. Befindet sich die Datei in einem Unterverzeichnis des konfigurierten Standardverzeichnisses, kann der Dateiname wie folgt eingegeben werden: subdir/file.txt |
Dateialter | Überprüft das Datum und die Uhrzeit des letzten Zugriffs auf die Datei. Wenn diese älter als der angegebene Wert sind, gibt der Job eine Warning aus (Datei zu alt). Das Alter der Datei kann in Minuten oder Sekunden eingegeben werden, Formate wie „1h 30m“ werden ebenfalls unterstützt. |
Alter des Dateiinhalts | Prüft, ob sich der Inhalt der Datei geändert hat. Wenn er sich während der hier eingegebenen Zeit nicht geändert hat, gibt der Job eine Warning aus (Dateiinhalt zu alt). Das Format für das Alter des Dateiinhalts ist das gleiche wie für den Parameter „Alter der Datei”. |
Transformieren → Ausführung | Wenn die vom Job bereitgestellte automatische Transformation aus irgendeinem Grund nicht ausreicht, kann die Datei vor dem Parsen mit einer der folgenden Optionen vorverarbeitet werden: Nicht verwendet (keine Vorverarbeitung) |
Sequenz | Siehe nächster Abschnitt |
Über die Dropdown-Liste „Tags“ können vordefinierte Variablen in die Felder oben eingegeben werden, z. B. $NAME$ für den Namen des Auftrags.
Standard-Datei-Transformationen
Wenn eine Datei von einem anderen System als Linux abgerufen wurde, müssen einige Sonderzeichen für die Analyse angepasst werden. Die folgende Liste zeigt, welche Fälle vom Job automatisch verarbeitet werden:
Windows-Zeilenumbruchzeichen werden entfernt (früher durch die Transformationsoption „dos2unix“ durchgeführt).
Wenn die Datei in UTF-8 mit BOM (Byte Order Mark) kodiert ist, wird die BOM entfernt
Wenn die Datei in Unicode (Big-Endian UTF-16 oder Little-Endian UTF-16) kodiert ist
Wenn keine Transformation definiert ist, wird die Datei vor dem Parsen in UTF-8 konvertiert
Wenn eine Transformation definiert ist, wird nichts an der Datei geändert (es wird davon ausgegangen, dass die Transformation die Datei korrekt verarbeitet)
Falls die Transformation fehlschlägt, werden in den Antwort- und Fehlercodes des Auftrags die folgenden Meldungen angezeigt:
Der Antwortcode 11 (Datei konnte nicht transformiert werden) wird immer angezeigt und sollte als Alarm Limit konfiguriert werden
Der Fehlercode 1 (Systemfehler) oder 2 (interner Fehler) kann zusätzlich angezeigt werden.
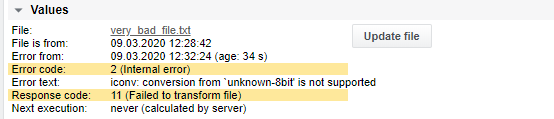
Parsefile-Sequenz
Allgemeines Verhalten
Wenn die Datei nicht gefunden wird, wird der Antwortcode auf 1 (Datei nicht gefunden) gesetzt und die Ausführung beendet.
Wenn „Dateialter” und/oder „Alter des Dateiinhalts” definiert sind, werden diese Prüfungen vor dem Parsen der Datei durchgeführt.
Wenn die Datei zu alt ist, wird der Antwortcode auf 2 (Datei zu alt) gesetzt, die Datei wird jedoch weiterhin geparst.
Wenn der Dateiinhalt zu alt ist, wird der Antwortcode auf 3 gesetzt (Dateiinhalt zu alt), die Datei wird jedoch weiterhin geparst.
Wenn eine Datei mehr als 100.000 Zeilen enthält, wird der Antwortcode auf 4 (Datei zu lang) gesetzt und die Ausführung wird beendet. Die Standardgrenze kann erhöht oder entfernt werden, indem die folgende Zeile in die SKOOR Engine-Konfigurationsdatei /opt/eranger/etc/eranger-collector.cfg eingefügt wird:
parsefile_line_limit = 1000000 raise limit to a million lines parsefile_line_limit = 0 remove limit altogether
Beim Hinzufügen neuer Werte, Zeichenfolgenwerte, Diff-Werte usw. sind innerhalb der Parsing-Sequenz maximal 32 Einträge für jeden Wertetyp möglich. Wenn Sie beispielsweise 3 Werte mit dem Element „Get value“ hinzufügen, beginnen Sie mit dem Hinzufügen von „Get value“ mit Index 1, dann 2, dann 3, wobei die Indexanzahl erhöht wird. Die Benutzeroberfläche erlaubt nur die Auswahl eines maximalen Index basierend auf der Anzahl der aktuell konfigurierten Sequenzelemente, damit die Dropdown-Liste für die Indexauswahl nicht zu viel Platz einnimmt.
Verfügbare Elemente in der Dropdown-Liste des Sequenzfilters
Set
Filter (einbeziehen)
Alle Zeilen in der Datei, die den Ausdruck nicht enthalten, werden ignoriert. Wenn Sie beispielsweise „localhost“ (ohne Anführungszeichen) eingeben, werden nur Zeilen berücksichtigt, die „localhost“ enthalten; andere Zeilen werden übersprungen.
Filter (ausschließen)
Dies funktioniert umgekehrt, d. h. als Negativfilter.
Alle Zeilen, die den Ausdruck enthalten, werden beim Parsen der restlichen Sequenz ignoriert.
Trennzeichen definieren
Das Standard-Spaltenbegrenzungszeichen ist ein Leerzeichen (1 Leerzeichen, mehrere aufeinanderfolgende Leerzeichen, Tabulatoren). Dadurch werden Zeilen effektiv in Wörter unterteilt.
Hier kann ein anderes Trennzeichen ausgewählt werden. Geben Sie eine Zeichenfolge aus mindestens einem Zeichen ein, z. B. „;“ oder „COL“. Während einer Sequenz kann das Trennzeichen mehrmals festgelegt und zurückgesetzt werden. Zum Zurücksetzen lassen Sie das Textfeld leer.
Die Spaltenanzahl beginnt bei 0 (Null).
Syslog-Modus
Wenn diese Option aktiviert ist, wird die Analyse mit der ersten neuen Zeile in der Datei fortgesetzt, die seit der letzten Ausführung des Auftrags hinzugefügt wurde.
Wenn die Datei rotiert wurde, wird die rotierte Datei ab der letzten EOF-Position verwendet, sodass keine Daten verloren gehen.
Groß-/Kleinschreibung ignorieren
Wenn diese Option aktiviert ist, wird die Groß-/Kleinschreibung bei Zeichenfolgenvergleichen ignoriert.
Nicht gefunden ignorieren
Wenn eine Zeile, ein Ausdruck oder eine Spalte nicht gefunden wird, wird der Antwortcode nicht auf 7 „Zeichenfolge nicht gefunden” gesetzt, sondern die Jobausführung wird beendet.
Nach Nicht-Auffinden fortsetzen
Wenn diese Option aktiviert ist, wird die Analyse fortgesetzt, nachdem eine Zeile oder Spalte nicht gefunden wurde.
Überlauf erkennen ein/aus
Wenn diese Option aktiviert ist, ignorieren alle Diff-Wert-Parameter, die später in der Sequenz folgen, Werte, die niedriger sind als der in der vorherigen Jobausführung gemessene Wert (nur positive Differenzen sind zulässig).
Dies wird hauptsächlich für Zähler verwendet. Die Einstellung kann später in der Sequenz deaktiviert werden.
Zeitstempel abrufen (Rate)
Ein Zeitstempel kann für exakte Berechnungen mit dem Sequenzparameter „Ratenwert abrufen” aus einer Datei gelesen werden. Beispielsweise, wenn die geparste Datei von einer asynchron ausgeführten Anwendung generiert wird.
Der Zeitstempel in der Datei muss in Sekunden, Millisekunden oder Mikrosekunden angegeben sein.
Suchen
Die folgenden Parameter beziehen sich auf Zeilen. Der Geltungsbereich für den nächsten Parameter ist die vom aktuellen Parameter gefundene Zeile. Wenn eine angeforderte Zeile nicht vorhanden ist, wird der Antwortcode auf 5 (Zeile nicht gefunden) gesetzt und die Ausführung beendet, es sei denn, „Weiter nach Nicht gefunden“ ist aktiviert.Gehe zu Zeile #
Der Parsing-Zeiger wird an den Anfang der entsprechenden Zeile gesetzt.
Zur nächsten Zeile
Der Parsing-Zeiger wird am Anfang der nächsten Zeile positioniert.
Zur ersten Zeile mit
Der Parsing-Zeiger wird am Anfang der ersten Zeile positioniert, die die Zeichenfolge/den Ausdruck auswertet.
Wenn keine Zeile mit einem solchen Ausdruck gefunden werden kann und „Weiter nach Nicht gefunden“ eingestellt ist, wird der Parsing-Zeiger am ersten Zeichen der ersten Zeile in der Datei positioniert und der Rest der Sequenz verarbeitet.
Zur nächsten Zeile mit
Der Parsing-Zeiger wird am Anfang der nächsten Zeile positioniert, die die Zeichenfolge/den Ausdruck auswertet.
Wenn keine Zeile mit einem solchen Ausdruck gefunden werden kann und „Weiter nach Nicht-Fund“ eingestellt ist, wird der Parsing-Zeiger auf das erste Zeichen der nächsten Zeile gesetzt und der Rest der Sequenz verarbeitet.
Zur letzten Zeile gehen mit
Der Parsing-Zeiger wird am Anfang der letzten Zeile positioniert, die die Zeichenfolge/den Ausdruck auswertet.
Wenn keine Zeile mit einem solchen Ausdruck gefunden werden kann und „Weiter nach Nicht-Fund“ eingestellt ist, wird der Parsing-Zeiger auf das erste Zeichen der ersten Zeile in der Datei gesetzt und der Rest der Sequenz verarbeitet.
Basierend auf Trennzeichen
suchen Die folgenden Befehle hängen von der Definition eines Trennzeichens ab. Wenn kein Trennzeichen definiert ist, werden Leerzeichen (Leerzeichen oder Tabulatoren) als Trennzeichen verwendet.Gehe zu Spalte #
Der Parsing-Zeiger wird auf das erste Zeichen der entsprechenden Spalte (0..n) in der aktuellen Zeile gesetzt.
Wenn die Spalte nicht gefunden wird, wird der Antwortcode auf 6 (Spalte nicht gefunden) gesetzt und die Ausführung beendet.
Wenn die Spalte nicht gefunden wird und „Weiter nach Nicht gefunden“ gesetzt ist, wird die Position des Parsing-Zeigers nicht geändert.
Der Geltungsbereich der folgenden Zeichenfolgenbefehle ist standardmäßig die gesamte Datei; wenn zuvor einer der Zeilenbefehle aufgerufen wurde, ist der Geltungsbereich die aktuelle Zeile.
Wenn das Feld leer gelassen wird, wird der Fehlercode auf 7 (Ungültiger Parameter) gesetzt und die Ausführung beendet.
Gehe zur ersten Zeichenfolge
Je nach Geltungsbereich wird nach dem ersten Vorkommen der Zeichenfolge in der gesamten Datei/in der aktuellen Zeile gesucht, das den Ausdruck auswertet.
Wird sie gefunden, wird der Parsing-Zeiger auf das erste Zeichen gesetzt, das den Ausdruck auswertet, und dann um die Länge des Ausdrucks erhöht.
Andernfalls wird die Ausführung beendet und der Antwortcode auf 7 (Zeichenfolge nicht gefunden) gesetzt, es sei denn, „Nicht gefunden ignorieren“ oder „Nach Nicht-Gefunden fortfahren“ wurde oben festgelegt.
Zur nächsten Zeichenfolge springen
Wie oben, aber die Suche beginnt an der aktuellen Position, sodass der Parser nach dem nächsten Vorkommen sucht.
Zur letzten Zeichenfolge gehen
Wie oben, aber der Parser sucht nach dem letzten Vorkommen eines Ausdrucks.
Die folgenden Parameter unterstützen die Ereignisbehandlung gemäß dem Agent Eventlog-Job und können bis zu 4 Ereignisse verfolgen.
Ereignis
EreignisX festlegen
Ein Ereignis wird gesetzt, wenn eine Zeile mit einem bestimmten Ausdruck oder einer bestimmten Zeichenfolge übereinstimmt.
Es können bis zu 32 Ereignisse konfiguriert und gesetzt werden.
Ereignis X zurücksetzen
Ein Ereignis wird zurückgesetzt, wenn eine nachfolgende Zeile mit einem bestimmten Ausdruck übereinstimmt.
Es können bis zu 32 Rücksetzereignisse konfiguriert und gesetzt werden.
EreignisX zurücksetzen nach
Ein Ereignis wird nach einer bestimmten Zeitüberschreitung (z. B. 10 m = 10 Minuten) zurückgesetzt.
Es können bis zu 32 Zeitüberschreitungen konfiguriert und eingestellt werden.
Die Rücksetzbedingung wird nur zur Laufzeit des Auftrags ausgewertet. Wenn ein Ereignis festgelegt wurde und während der nächsten Auftragsausführung keine neuen entsprechenden Zeichenfolgen gefunden werden, wird das Ereignis zurückgesetzt, sobald die oben genannte Zeitüberschreitung erreicht ist.
Werte
Wert abrufen
Beginnend an der aktuellen Position wird ein numerischer Wert gesucht und bei Auffinden zugewiesen.
Andernfalls wird der Antwortcode auf 8 gesetzt (Wert nicht gefunden) und die Ausführung wird beendet.
Der Parsing-Zeiger wird auf das erste Zeichen nach dem gefundenen Wert gesetzt.
Durch Drücken der Taste „Unit“ wird das folgende Dialogfeld angezeigt: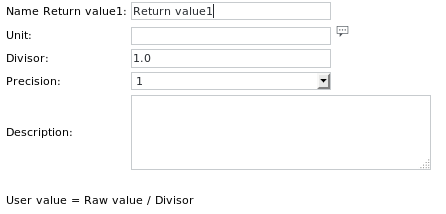
Hier kann man angebenden Namen des zurückzugebenden Werts (optional)
seine Einheit (z. B. Sekunden, optional)
einen Divisor, durch den der Wert geteilt werden soll (optional)
die numerische Ausgabegenauigkeit (z. B. 1,000)
Differenzwert X abrufen
Beginnend an der aktuellen Position wird nach einem numerischen Wert gesucht und die Differenz zum Wert, der bei der letzten Ausführung gefunden wurde, zugewiesen.
Der Parsing-Zeiger wird auf das erste Zeichen nach dem gefundenen Wert gesetzt.
Differenzwert abrufenX
Der Ratenwert stellt die Differenz zwischen dem aktuellen Wert und dem letzten Wert geteilt durch die zwischen den beiden Messungen verstrichene Zeit (in Sekunden) dar:
(Valnow - Vallast) / (tnow - tlast)
Normalerweise wird für diese Berechnung der Zeitstempel der Jobausführung verwendet. Er kann jedoch auch mithilfe des Elements „Zeitstempel (Rate) abrufen” (siehe oben) aus der Datei gelesen werden.
Wenn die Zeitstempel-Differenz <= 0 ist, wird kein neuer Ratenwert generiert.
Zeichenfolgenwert abrufenX
Hiermit kann ein Zeichenfolgenwert aus einer Datei empfangen werden. Verwenden Sie diese Option nur für Zeichenfolgen, die sich nicht häufig ändern, d. h. wenn die Zeichenfolge zu den wenigen Zeichenfolgen gehört, von denen bekannt ist, dass sie Teil des geparsten Textes sind.
Die Zeichenfolge kann mithilfe der Konfigurationsfelder, die durch Klicken auf die Schaltfläche „Einheit“ zugänglich sind, einem numerischen Wert zugeordnet werden.
Zeichenfolge vergleichenX
Der Ausdruck (der eine einfache Zeichenfolge, aber auch ein regulärer Ausdruck sein kann) wird ausgewertet und entweder 1 (Gefunden) oder 0 (Nicht gefunden) als Rückgabewert zugewiesen.
Der Name des oben genannten Rückgabewerts und der Text, der neben dem Rückgabewert angezeigt wird, können durch Klicken auf die Schaltfläche „Enum“ rechts neben diesem Parameter beeinflusst werden. Dadurch wird das folgende Dialogfeld geöffnet:

Der Dialog zeigt bei einem erfolgreichen Vergleich im Abschnitt „Werte“ Folgendes an: Status
prüfen: 1 (Status ist OK)
anstelle der Standardeinstellung:
Vergleichsergebnis 1: 1 (Gefunden)
Auf diese Weise kann der Rückgabewert einer bestimmten Meldung zugeordnet werden.Die Sonderzeichen ^ oder $ können verwendet werden, um nach Ausdrücken am Anfang oder Ende einer Zeile zu suchen. Wenn Sie beispielsweise „^AAA“ (ohne Anführungszeichen) eingeben, wird „Gefunden“ zurückgegeben, wenn die Zeichenfolge „AAA“ am Anfang der Zeile steht. Wenn die Zeile jedoch etwas anderes als „AAA“ enthält, aber nicht mit „AAA“ beginnt, wird „Nicht gefunden“ zurückgegeben. Ebenso wird bei Eingabe von „AAA$“ die Zeichenfolge nur gefunden, wenn sie am Ende der Zeile steht.
Wenn eine Reihe von Zeichenfolgen-/Wertkombinationen im Format „1=AAA, 2=BBB“ oder „1=AAA,2=BBB,0=*“ eingegeben wird und eine Zeichenfolge der Reihe nach der aktuellen Position in der aktuellen Zeile gefunden wird, wird die entsprechende Zahl als Ausgabewert zugewiesen (das zweite Beispiel gibt 0 für Zeichenfolgen zurück, die nicht in der Reihe enthalten sind). Dadurch sind mehr Rückgabewerte als die Standardwerte 0 oder 1 möglich. Zusätzlich können diese Rückgabewerte dann mithilfe des Felds „Enum“ weiteren Ausgabemeldungen zugeordnet werden.
Sonderzeichen, die normalerweise Teil eines regulären Ausdrucks sind, z. B. „(“, müssen mit einem Backslash maskiert werden, damit sie korrekt abgeglichen werden können.
Der Parsing-Zeiger wird auf das erste Zeichen nach dem ausgewerteten Ausdruck gesetzt, das kein Leerzeichen, Tabulator oder vertikales Strichzeichen (| oder ¦) ist, oder auf die nächste Spalte, wenn ein Trennzeichen definiert wurde.
Anzahl der ZeichenfolgenübereinstimmungenX
Wenn ein Zeilenparameter in der oben genannten Reihenfolge ausgegeben wurde, werden alle Vorkommen einer Zeichenfolge in der aktuellen Zeile gezählt, andernfalls werden alle Vorkommen der Zeichenfolge in der gesamten Datei gezählt.
Der Parsing-Zeiger wird nicht verschoben.
Text zur Info-Meldung
Der Text von der aktuellen Position des Parsing-Zeigers bis zum Ende der Zeile wird in die Info-Meldung kopiert. Wenn kein Text vorhanden ist, wird der Antwortcode auf 9 gesetzt (Text für Info nicht gefunden) und die Ausführung wird beendet.
Der Parsing-Zeiger wird nicht verschoben.
Parsefile-Werte und Alarm Limits
Der Parsedatei-Job kann je nach den anderen konfigurierten Alarm Limits in den Wartungszustand „Maintenance OK” oder „Maintenance Major” wechseln. Wenn beispielsweise die folgende Alarm Limit konfiguriert ist:
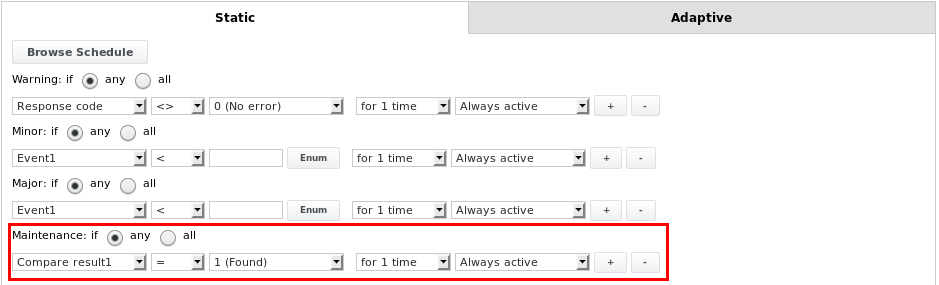
Der Job wechselt in den Status „Maintenance OK“, wenn der Textvergleich mit einer bestimmten Zeichenfolge oder einem bestimmten Ausdruck übereinstimmt und sich ansonsten im Status „OK“ befindet. Dies kann verwendet werden, um den Job und sein übergeordnetes Gerät (die Wartung wird von einem Job nach oben auf sein Gerät übertragen) in den Wartungsmodus zu versetzen, je nachdem, was beim Parsen einer Datei gefunden wird, die Informationen zum Wartungsstatus enthält, z. B. von anderen Überwachungssystemen wie Nagios. Alle anderen Alarm Limits unten können auch in dem Alarm Limit „Wartung” verwendet werden.
Wert / Alarm Limit | Beschreibung |
|---|---|
Ereignis1-X | Überprüft, ob ein Ereignis basierend auf dem oben genannten Parameter „Ereignissequenz festlegen” ausgelöst wurde. |
Rückgabewert1-X | Benutzerdefinierter numerischer Wert basierend auf dem oben genannten Sequenzparameter „Wert abrufen“. |
Rate value1-X | Benutzerdefinierter numerischer Ratenwert basierend auf dem oben genannten Sequenzparameter „Get rate value“ (Ratenwert abrufen). |
Differenzwert1-X | Benutzerdefinierter numerischer Differenzwert basierend auf dem oben genannten Sequenzparameter „Get diff value“ (Differenzwert abrufen). |
Zeichenfolgenwert1-X | Benutzerdefinierter Zeichenfolgenwert basierend auf dem oben genannten Sequenzparameter „Zeichenfolgenwert abrufen“. |
Vergleichsergebnis1-X | Benutzerdefinierter Wert basierend auf dem oben genannten Sequenzparameter „Zeichenfolgenwert vergleichen“. |
Übereinstimmungszähler1-X | Benutzerdefinierter Wert basierend auf dem oben genannten Sequenzparameter „Zeichenfolgenübereinstimmungen zählen“. |
Antwortcode | 0 Kein |
Fehlercode | Generischer Job-Fehlercode (siehe Abschnitt „Job-Fehlercodes“) |
Beispiele für Parsefile
Beispiel 1 – Parsen einer Datei „file.txt” mit folgendem Inhalt, um die 3 Werte in den letzten 3 Zeilen zu lesen:
11;OK;33;44.9888;MK;Duration (average): 203.6533s Open cases: 10 8 1
Die Jobkonfiguration sieht wie folgt aus:
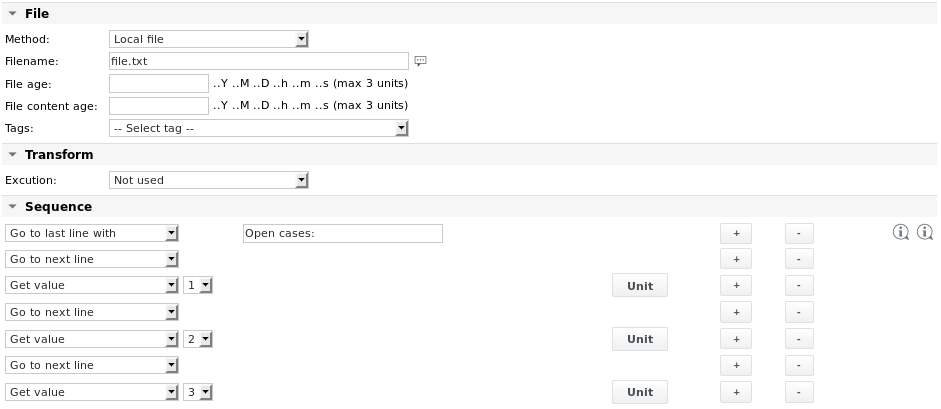
Die Einheitsdefinition des ersten Get-Wert-Elements lautet:
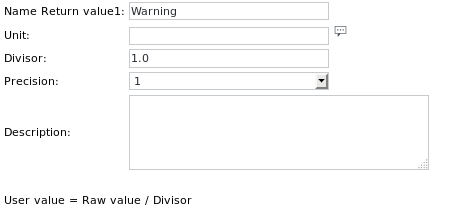
Die beiden anderen Einheitsdefinitionen sind ähnlich und heißen Minor bzw. Major.
Ausgabe 1
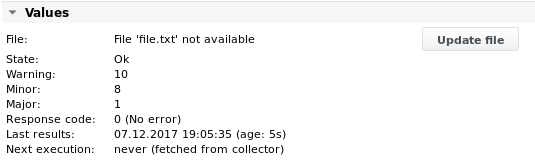
Beispiel 2 – Parsen Sie dieselbe Datei „file.txt“ und extrahieren Sie Werte aus der ersten Zeile basierend auf Spalten
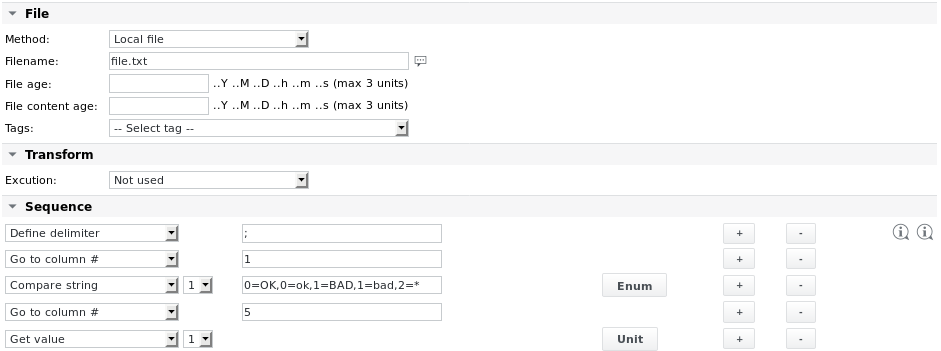
Die Enum-Definition des Elements „Compare string 1“ lautet:

Gesamter Text: 0=Status ist gut, 1=Status ist nicht so gut, 2=Status ist unbekannt
Die Unit-Definition für Get value 1 lautet:
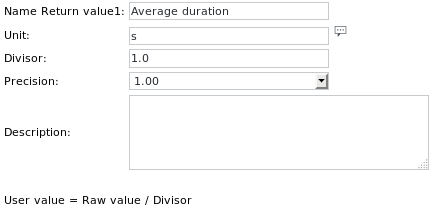
Beachten Sie die erhöhte Genauigkeit, um Fließkommawerte lesen zu können.
Ausgabe 2
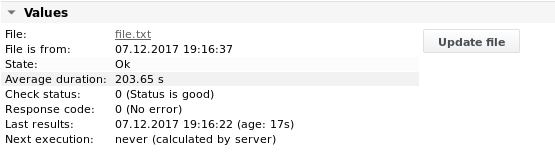
Beispiel 3 – Suche nach einer Zeile, die den Namen des Servers enthält, unter Verwendung von Variablen-Tags. Bleiben Sie in dieser Zeile und rufen Sie die Werte „MeasurementValue1“ und „CPU_Usage“ ab.
Der Dateiinhalt lautet:
Timestamp=Fri Oct 31 09:55:20 CET 2017 ServerName=myserver01;MeasurementValue1=1.11;CPU_Usage=10%;EnumValue1=OK; ServerName=myserver02;MeasurementValue1=1.22;CPU_Usage=22%;EnumValue1=BAD;
Der Name des Geräts lautet myserver01.
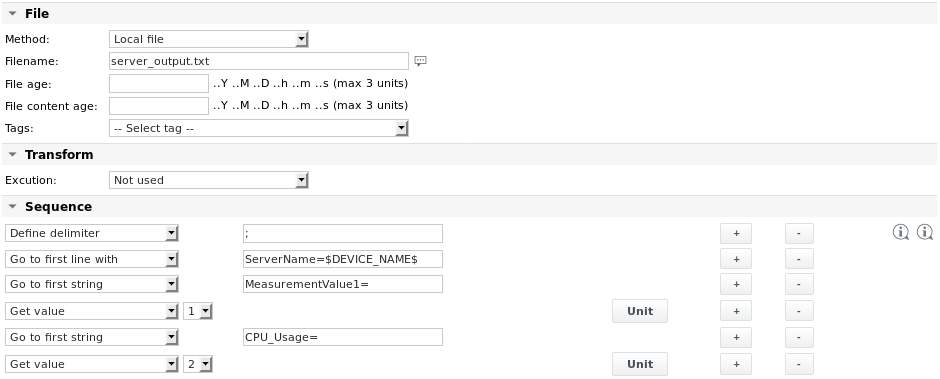
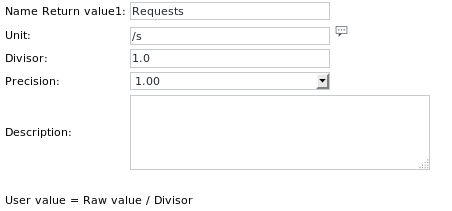
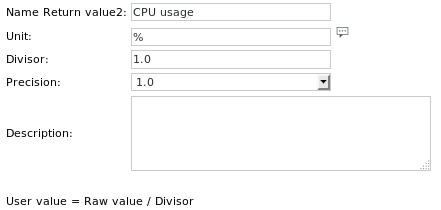
Die Einheitsdefinitionen lauten:
Durch die Verwendung von SKOOR Engine-Tags können Aufträge auf verschiedene Geräte kopiert werden, wobei sie weiterhin mit dem richtigen Gerätenamen funktionieren.
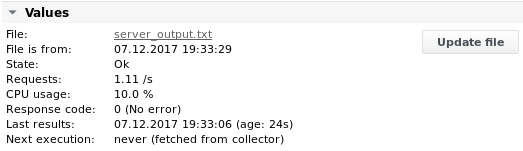
Ausgabe 3
Beispiel 4 – Lesen Sie einen Zeitstempel aus einer regelmäßig generierten Datei und lesen Sie den Ratenwert, um die Anzahl der eingehenden und ausgehenden Pakete auf einer Netzwerkschnittstelle zu erhalten.
Die Datei wird regelmäßig mit dem folgenden Inhalt aus einem Execute-Job mit dem folgenden Inline-Skriptinhalt generiert:
date +%s%N | cut -c1-13 netstat -I=eth0
Die erste Zeile gibt den Zeitstempel (Sekunden seit dem 1.1.1970) mit einer Genauigkeit von Millisekunden aus, die zweite Zeile gibt die Empfangs-/Sende-Statistiken auf der Netzwerkschnittstelle eth0 aus. Die generierte Datei lautet:
1512726065120 Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 5761332 0 0 0 2932100 0 0 0 BMRU
Die Ratenwerte (eingehende und ausgehende Pakete) sind unabhängig von den Ausführungsintervallen sowohl des Execute-Jobs als auch des Parsefile-Jobs. Normalerweise würde man den Execute-Job und den Parse-Job unter einen Batch-Job setzen und ihnen ein Ausführungsintervall ohne Wiederholung zuweisen, sodass nur der Batch-Job ein Ausführungsintervall hätte.
Der parsefile-Job sieht wie folgt aus:
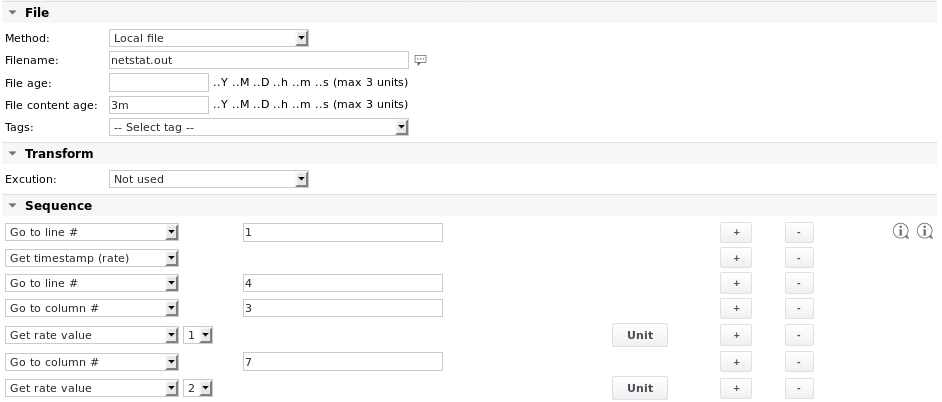
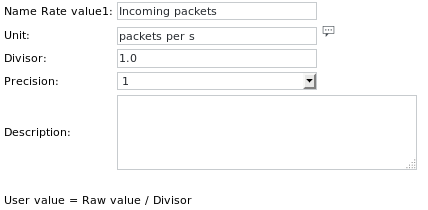
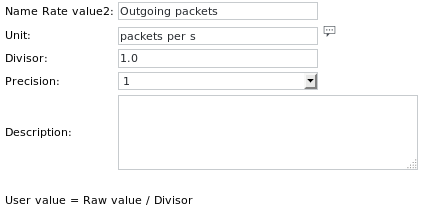
Die Unit-Definitionen lauten:
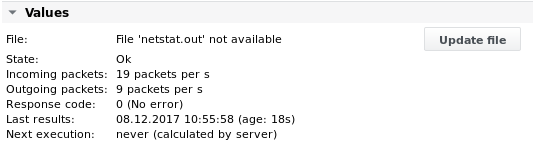
Ausgabe 4
Die Werte werden nach der zweiten Ausführung des Jobs ausgegeben (der Ratenwert muss mit der vorherigen Messung verglichen werden):
Beispiel 5 – Ereignisse aus geparsten Inhalten generieren
Lesen Sie eine durch einen externen Job generierte Datei und suchen Sie nach bestimmten Zeichenfolgen. Generieren Sie ein Ereignis1, wenn die Zeichenfolge „Error” gefunden wird. Setzen Sie das Ereignis nach einer bestimmten Zeit zurück. Generieren Sie auch ein Ereignis2, wenn die Zeichenfolge „Process mysqld terminated” gefunden wird. Setzen Sie das zweite Ereignis nur zurück, wenn die Zeichenfolge „Process mysqld started” weiter unten in der Datei oder während der nächsten Jobausführung gefunden wird.
In diesem Beispiel legt das erste Element in der Parsing-Sequenz den Parameter „Syslog-Modus” fest. Dadurch wird sichergestellt, dass nur neue Daten in der Datei analysiert werden. Die älteren Teile der Datei, die während der letzten Jobausführung analysiert wurden, werden für nachfolgende Jobausführungen nicht mehr berücksichtigt. Wenn der erste Joblauf die Zeichenfolge „Error” in der Datei findet, setzt er das Ereignis1. Wenn während der nächsten 10 Jobausführungen (das Jobintervall ist auf 1 Minute eingestellt) keine neuen Fehlerzeichenfolgen gefunden werden, wird das Ereignis zurückgesetzt.
Der Ereignismechanismus ermöglicht es dem Job, nach einer bestimmten Zeit in den Status „OK“ zurückzukehren, während weiterhin die Möglichkeit besteht, eine Alarm-E-Mail auszulösen, wenn ein Ereignis gesetzt wird.
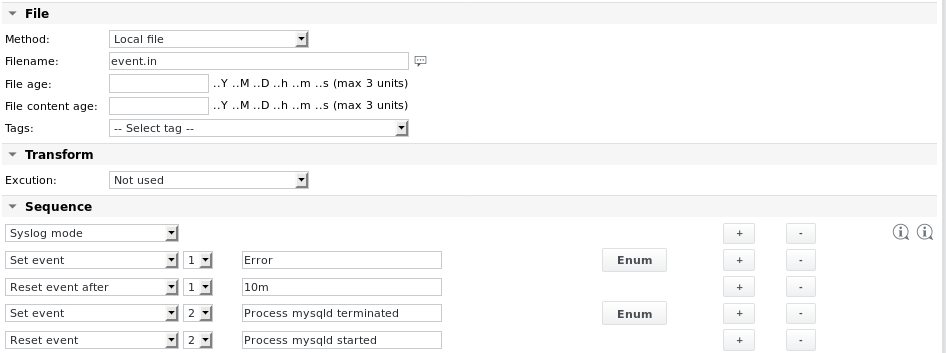
Die Enum-Definitionen lauten wie folgt:


Die Alarm Limits sind wie folgt konfiguriert:
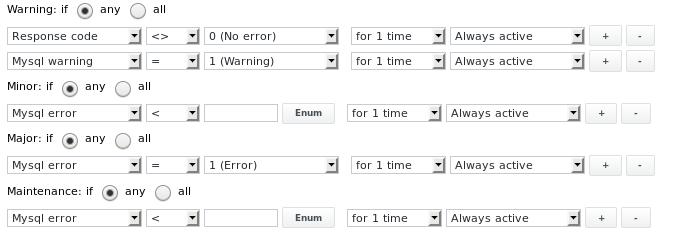
Ausgang 5