Konzept der Datenbankreplikation
Architektur
Die SKOOR Engine verwendet eine PostgreSQL-Datenbank, um ihre Konfigurationsdaten sowie ihre historischen Werte und Verlaufsdaten zu speichern. Sie unterstützt die Verwendung einer Primär-/Standby-Konfiguration, um den Inhalt der Datenbank kontinuierlich zu replizieren. Dabei kommen die eigenen Replikationsmethoden von PostgreSQL zum Einsatz, was bedeutet, dass eine exakte Kopie der Datenbank auf dem Primärserver auf dem Standby-Server gespeichert wird und alle Aktualisierungen der Datenbank auf dem Primärserver sofort auf den Standby-Server repliziert werden. Der Primärserver puffert die SQL-Anweisungen in einem Binärprotokoll, der Standby-Server fordert diese Anweisungen vom Server an.
Dies gewährleistet kurze Ausfallzeiten im Falle von Hardwarefehlern. Es schützt jedoch NICHT vor Bedienungsfehlern wie fehlerhaften Löschanweisungen, die sofort mit dem Standby-Server synchronisiert werden. Die Replikation ersetzt keine regelmäßigen Backups.
Die folgende Abbildung zeigt ein Beispiel für ein Standard-Replikationslayout.
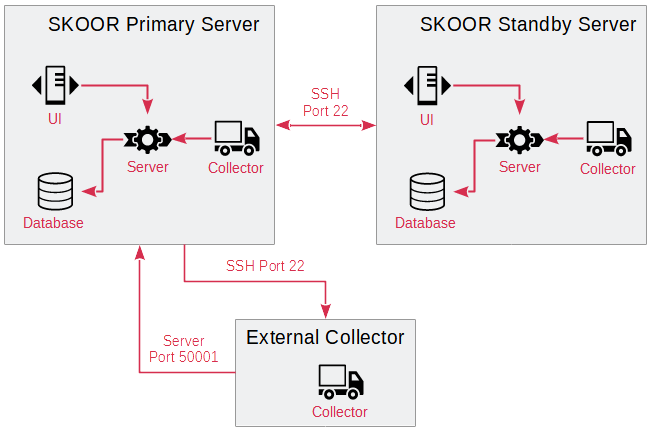
Im Standardmodus trägt der Primärserver die gesamte Last, alle Benutzeranfragen werden vom Apache-Webserver auf dem Primärserver beantwortet, die Messdaten werden von den Kollektoren an den aktuellen Primärserver geliefert und in der Datenbank gespeichert. Die Dienste eranger-server, eranger-collector und eranger-report laufen NICHT auf dem Standby-Server.
Hauptmerkmale des Replikationssetups
Die Replikation kann auch mit externen SKOOR Collectoren implementiert werden.
Wenn zuvor eine Replikation durchgeführt wurde, ist wahrscheinlich ein großer Teil der Datenbankdateien bereits synchronisiert. Das Skript überträgt KEINE alten Tabellen, die bereits synchronisiert sind. Dies spart Netzwerkbandbreite, wenn eine Neuinitialisierung durchgeführt werden muss.
Es gibt kein automatisches Failover vom Primär- zum Standby-Server. Diese Entscheidung soll bewusst dem Menschen überlassen bleiben. Das Skript unterstützt jedoch einen nicht-interaktiven Modus, der die Ausgabe eines Failovers durch ein Skript ermöglicht (Option -f).
Möglichkeit, den Primärserver vom Standby-Server aus zu überwachen (unabhängig von SKOOR), indem eine E-Mail gesendet wird, sobald festgestellt wird, dass die SKOOR Engine auf dem aktuellen Primärserver nicht mehr läuft.
Möglichkeit, benutzerdefinierte Skripte oder Befehle vor und/oder nach dem Umschalten der Serverfunktionen (Standby zu primär und umgekehrt) auszuführen.
Anforderungen
Um die Datenbankreplikation einzurichten, ist ein zweiter SKOOR Server mit den gleichen Leistungsspezifikationen wie der erste erforderlich. Obwohl sich dieser Standby-Server die meiste Zeit im Standby-Modus befindet, muss er in der Lage sein, die volle Last zu tragen, wenn seine Funktion von Standby zu primär wechselt.
Die folgenden Voraussetzungen müssen erfüllt sein:
Auf Primär- und Standby-Server ist dieselbe Version von SKOOR installiert.
(Optional) Externe Kollektoren sind korrekt eingerichtet und funktionieren.
Der Parameter „server<N>_address” muss auf dieselbe IP-Adresse wie der primäre Server eingestellt sein.
Kollektoren, die das HTTP-Protokoll verwenden, können nicht automatisch umgeschaltet werden.
Die Datei /opt/eranger/bin/eranger-server-replication.pl ist auf dem Primärserver, dem Standby-Server und allen Kollektoren identisch. Das bedeutet, dass auf allen beteiligten Hosts dieselbe SKOOR-Version installiert sein muss.
Die Datei /etc/opt/eranger/eranger-replication.cfg ist korrekt konfiguriert und auf dem Primär-, Standby- und allen Kollektoren identisch.
Netzwerkkonnektivität
TCP-Port 22 (ssh) vom Primär- zum Standby-Server, umgekehrt und vom Primär- und Standby-Server zu allen externen Kollektoren.
TCP-Port 50001 (SKOOR Collector-Datenübertragung) von allen externen Kollektoren zum Primär- und Standby-Server.