Concept de réplication de base de données
Architecture
The SKOOR Engine uses a PostgreSQL database to store its configuration data as well as its historical values and historical data. It supports the use of a master/slave configuration to continuously replicate the database contents. Les méthodes de réplication propres à PostgreSQL sont utilisées, ce qui signifie qu’une copie exacte de la base de données du serveur principal est conservée sur le serveur de secours et que toutes les mises à jour apportées à la base de données du serveur principal sont immédiatement répliquées vers le serveur de secours. Le serveur principal met en mémoire tampon les instructions SQL dans un journal binaire, tandis que le serveur de secours récupère ces instructions auprès du serveur principal.
Cela garantit des temps d’indisponibilité courts en cas de défaillance matérielle. Cependant, cela ne protège PAS contre les erreurs humaines, telles que des instructions de suppression erronées, qui seront immédiatement synchronisées vers le serveur de secours. La réplication ne remplace pas les sauvegardes régulières.
La figure suivante illustre un exemple de configuration de réplication standard.
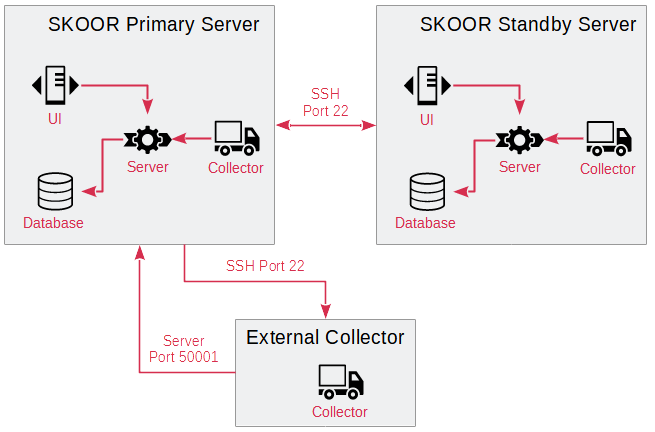
En mode par défaut, le serveur principal supporte toute la charge : toutes les requêtes des utilisateurs sont traitées par le serveur web Apache du serveur principal, les données de mesure sont transmises par les collecteurs au serveur principal actuel et stockées dans la base de données. Les services eranger-server, eranger-collector et eranger-report ne s’exécutent PAS sur le serveur de secours.
Principales caractéristiques de la configuration de réplication
La réplication peut être mise en œuvre même avec des SKOOR Collectors externes.
Si une réplication a déjà été lancée, une grande partie des fichiers de la base de données sera probablement déjà synchronisée. Le script ne transférera PAS les anciennes tables qui sont déjà synchronisées. Cela permet d’économiser de la bande passante réseau si une réinitialisation doit être effectuée.
Il n’y a pas de basculement automatique du serveur principal vers le serveur de secours. Le système a été conçu pour laisser cette décision à un utilisateur. Cependant, le script prend en charge un mode non interactif qui permettrait de déclencher un basculement via un script (option -f).
Possibilité de surveiller le serveur principal depuis le serveur de secours (indépendamment de SKOOR) en envoyant un e-mail dès qu’il détecte que le SKOOR Engine ne fonctionne plus sur le serveur principal actuel.
Possibilité d’exécuter des scripts ou des commandes personnalisés avant et/ou après la commutation des fonctions du server (de la machine de secours vers la machine principale et vice versa).
Configuration requise
Pour configurer la réplication de la base de données, un deuxième SKOOR Server est nécessaire, présentant les mêmes spécifications de performances que le premier. Bien que ce serveur de secours soit en mode de secours la plupart du temps, il doit être capable de supporter la charge complète lorsque sa fonction passe de « de secours » à « principal ».
Les conditions préalables suivantes doivent être remplies :
La même version de SKOOR est installée sur le serveur principal et le serveur de secours.
(Facultatif) Les collecteurs externes sont correctement configurés et fonctionnent
Le paramètre server<N>_address doit être défini sur la même adresse IP que celle du serveur principal
Les collecteurs utilisant le protocole HTTP ne peuvent pas être basculés automatiquement
Le fichier /opt/eranger/bin/eranger-server-replication.pl doit être identique sur le serveur principal, le serveur de secours et tous les collecteurs. Cela signifie que tous les hôtes concernés doivent disposer de la même version de SKOOR.
Le fichier /etc/opt/eranger/eranger-replication.cfg est correctement configuré et identique sur le serveur principal, le serveur de secours et tous les collecteurs.
Connectivité réseau
Port TCP 22 (ssh) entre le serveur principal et le serveur de secours, et inversement, ainsi qu’entre le serveur principal, le serveur de secours et tous les collecteurs externes.
Port TCP 50001 (transfert des données des collecteurs SKOOR Collector) depuis tous les collecteurs externes vers le serveur principal et le serveur de secours.