Parsefile
Function | Parse a file for text and/or values, build differential values. Up to 32 values / string values / diff values / rate values / compare results / match counters and events are possible per parse job |
|---|---|
Alarming | String matches, String counts, Values, String values, Diff values, Rate values, Events, File age, File content age, Response code Special: The job can enter the state Maintenance OK or Maintenance Major, based on configured alarm limits. |
Parsefile detail

Parsefile parameters
Parameter | Description |
|---|---|
Method | The file to be parsed can be either a Local file (default) or it can be fetched first using one of the following protocols: HTTP If one of the remote protocols is chosen, additional parameters are shown for source path and user authentication. See Fetchfile job for configuration details. Example: fetch file first from a webserver, before parsing it: Fetching a remote file from within the Parsefile job is the preferred way. An alternative would be to create a Batch job with a Fetchfile or Agent Fetchfile job and a Parsefile job. If the remote system is running on Windows and the SKOOR WinAgent is installed, files can also be fetched using the WinAgent. WinAgent is listed in the method dropdown, as soon as the Agent username and Agent password properties are set on the jobs device. On Windows 10, OpenSSH server can be installed from the optional features. After starting the respective service, files can be copied using scp. |
Filename | The filename to parse. The path can be specified relative to the default parse directory on the collector (defined in the file /etc/opt/eranger/eranger-collector.cfg, normally set to /var/opt/run/eranger/collector/tmp) or absolute. If the file is located in a subdirectory of the configured default directory, then the file name can be entered as: subdir/file.txt |
File age | Tests the last access date and time to the file. If it is older then the given value, the job issues a warning (File too old). File age may be entered in minutes or seconds, formats like “1h 30m” are also supported. |
File content age | Tests if the file contents has changed. If it has not changed during the time entered here, the job issues a warning (File content too old). File content age format is the same as for the File age parameter. |
Transform → Execution | If the automatic transformation provided by the job is not sufficient for some reason, the file can be preprocessed by one of the following options before parsing it: Not used (No preprocessing) |
Sequence | See next section |
The Tags dropdown list allows entering pre-defined variables into the fields above, e.g. $NAME$ for the name of the job.
Standard file transformations
If a file was fetched from a system other than linux, some special characters must be adapted for the parsing. The following list shows which cases are handled by the job automatically:
Windows carriage return characters are removed (formerly done by the dos2unix transform option)
If the file is encoded in UTF-8 with BOM (Byte Order Mark), the BOM is removed
If the file is encoded in unicode (big-endian UTF-16 or little-endian UTF-16)
If no transformation is defined, the file is converted to UTF-8 before parsing
If a transformation is defined, nothing is done to the file (it is assumed the transformation handles the file correctly)
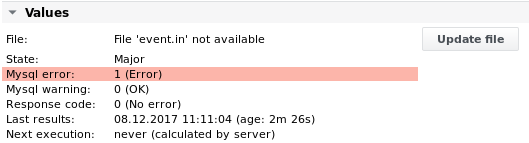
In case the transformation fails, the job's Response and Error codes will display the following messages:
Response code 11 (Failed to transform file) will always be displayed and should be configured as alarm limit
Error code 1 (System error) or 2 (Internal error) can be displayed additionally
Parsefile sequence
General behaviour
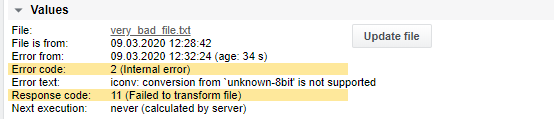
If the file is not found, the response code is set to 1 (File not found) and the execution is terminated.
If File age and/or File content age is defined, these checks are done before parsing the file.
If the file is too old, the response code is set to 2 (File too old), however, the file is still parsed.
If the file content is too old, the response code is set to 3 (File content too old) however, the file is still parsed.
If a file contains more than 100000 lines the response code is set to 4 (File too long) and the execution is terminated. The default limit can be raised or removed by adding the following line in the SKOOR Engine configuration file /opt/eranger/etc/eranger-collector.cfg:
parsefile_line_limit = 1000000 raise limit to a million lines parsefile_line_limit = 0 remove limit altogether
When adding new values, string values, Diff values etc, a maximum of 32 entries are possible within the parse sequence for each value type. For example, when adding 3 values using the Get value item, start with adding Get value with index 1, then 2, then 3, with increasing index count. The user interface only allows selecting a maximum index based on the number of currently configured sequence items so the index selection dropdown list doesn't take up too much space.
Available items in the sequence filter dropdown list
Set
Filter (include)
All lines in the file which do not contain the expression are ignored, e.g. entering “localhost” (without quotes) will consider only lines containing "localhost"; other lines are skipped.
Filter (exclude)
This works the other way around, i.e. as a negative filter.
All lines containing the expression are ignored for parsing the rest of the sequence.
Define delimiter
The default column delimiter is whitespace (1 space, several consecutive spaces, tabs). This effectively divides lines into words.
A different delimiter can be chosen here. Enter a string of 1 or more characters like ";" or "COL". During a sequence the delimiter can be set and reset several times. To reset, leave the text field empty.
Column count starts at 0 (zero).
Syslog mode
If this is set, parsing continues with the first new line in the file added since the last run of the job.
If the file has been rotated, the rotated file is used from the last EOF position so no data are lost.
Ignore case
If this is set, case is ignored for string comparisons.
Ignore not found
If a line or expression or column is not found, response code is not set to 7 String not found, but the job execution is terminated.
Continue after not found
If this is set, parsing is continued after a line or column has not been found.
Detect overflow on/off
If this is enabled, any Diff value parameters following later in the sequence will ignore values which are lower than the value measured in the previous job execution (only positive differences allowed).
This is mostly used for counters. The setting can be turned off later in the sequence.
Get timestamp (rate)
A timestamp may be read from a file for exact calculations using the sequence parameter Get rate value. For example, if the parsed file is generated by an asynchronously executed application.
The timestamp in the file must be printed in units of seconds, ms or µs.
Find
The following parameters refer to lines. The scope for the next parameter is the line found by the current parameter. If a requested line does not exist, the response code is set to 5 (Line not found) and the execution is terminated, except if Continue after not found is set.Go to line #
The parse pointer is positioned at the beginning of the corresponding line.
Go to next line
The parse pointer is positioned at the beginning of the next line.
Go to first line with
The parse pointer is positioned at the beginning of the first line which evaluates the string/expression.
If a line with such an expression cannot be found and “Continue after not found” is set, the parse pointer is positioned at the first character of the first row in the file and the rest of the sequence is processed.
Go to next line with
The parse pointer is positioned at the beginning of the next line which evaluates the string/expression.
If a line with such an expression cannot be found and “Continue after not found” is set, the parse pointer is positioned at the first character of the next row and the rest of the sequence is processed.
Go to last line with
The parse pointer is positioned at the beginning of the last line which evaluates the string/expression.
If a line with such an expression cannot be found and “Continue after not found” is set, the parse pointer is positioned at the first character of the first row in the file and the rest of the sequence is processed.
Find delimiter based
The following commands depend on the definition of a delimiter. If no delimiter is defined, whitespace (spaces or tabs) is used as delimiterGo to column #
The parse pointer is positioned at the first character of the corresponding column (0..n) in the current line.
If the column is not found the response code is set to 6 (Column not found) and the execution is terminated.
If the column is not found and Continue after not found is set, the parse pointer position is not changed.
The scope of the following string commands defaults to the entire file; if one of the line commands has been called previously, the scope is the current line.
If the field is left empty, the error code is set to 7 (Invalid parameter) and the execution is terminated.
Go to first string
Depending on the scope, the first occurrence of the string in the entire file / in the current line which evaluates the expression, is searched.
If found, the parse pointer is positioned at the first character which evaluates the expression and then incremented by the length of the expression
Otherwise the execution is terminated and the response code is set to 7 (String not found), except if Ignore not found or Continue after not found has been set above.
Go to next string
Same as above, but the search starts at the current position so the parser will look for the next occurrence.
Go to last string
Same as above, but the parser looks for the last occurrence of an expression.
The following parameters support event handling according to the Agent Eventlog job and can track up to 4 events.
Event
Set eventX
An event is set when a line matches a given expression or string.
Up to 32 events can be configured and set.
Reset eventX
An event is reset when a subsequent line matches a given expression.
Up to 32 reset events can be configured and set.
Reset eventX after
An event is reset after a given timeout (e.g. 10m = 10 minutes).
Up to 32 timeouts can be configured and set.
The reset condition is evaluated only at job runtime. If an event has been set and no new corresponding strings are found during the next job execution, the event will be reset if the timeout above is reached.
Values
Get valueX
Beginning at the current position a numeric value is searched and assigned if found
Otherwise the response code is set to 8 (Value not found) and the execution is terminated.
The parse pointer is set to the first character after the value found.
Pressing the Unit button brings up the following dialog: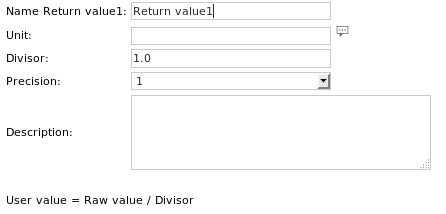
Here one can specifythe name of the value to be returned (optional)
its unit (e.g. seconds, optional)
a divisor by which the value should be divided (optional)
Numeric output precision (e.g. 1.000)
Get diff valueX
Beginning at the current position a numeric value is searched and the difference to the value found during the last execution is assigned.
The parse pointer is set to the first character after the value found.
Get rate valueX
The rate value represents the difference of the current value and the last value divided by the amount of time (seconds) that has passed between the two measurements:
(Valnow - Vallast) / (tnow - tlast)
Usually the timestamp of job execution is taken for this calculation. It can, however, also be read from the file by using the Get timestamp (rate) item (see above)
If the timestamp difference is <= 0 no new rate value is generated.
Get string valueX
This allows receiving a string value from a file. Use this only for strings that do not change often, i.e. use it when the string is one of a few strings known to be part of the parsed text.
The string may be mapped to a numeric value using the configuration fields accessible when clicking the Unit button.
Compare stringX
The expression (which may be a simple string, but can also be a regular expression) is evaluated and either 1 (Found) or 0 (Not Found) is assigned as return value.
The name of the above return value and the text which is shown next to the return value can be influenced by clicking the Enum button to the right of this parameter. This opens the following dialog:

which will show the following for a succesful comparison in the Values section:
Check status: 1 (Status is OK)
instead of the default:
Compare result1: 1 (Found)
This allows mapping the return value to a specific message.The special characters ^ or $ can be used to search for expressions at the beginning or end of a line. For example, entering “^AAA” (without quotes) will return Found if the string “AAA” is at the beginning of the line, however, it will return Not found if the line contains but starts with anything else than “AAA”. Likewise, entering “AAA$” will find the string only if it is located at the end of the line.
If a set of string/value combinations in the format "1=AAA, 2=BBB" or "1=AAA,2=BBB,0=*" is entered and a string of the set is found after the current position on the current line, the appropriate number is assigned as an output value (the second example returns 0 for strings not in the set). This allows for more return values than the default of 0 or 1. Additionally, these return values can then be further mapped to output messages using the Enum field.
Special characters that are usually part of a regular expression, e.g. “(“, need to be escaped with a backslash to be matched correctly.
The parse pointer is set to the first character after the evaluated expression which is not one of blank, tab or vertical bar (| or ¦) or to the next column if a delimiter has been defined.
Count string matchesX
If a line parameter has been issued in the sequence above, all occurrences of a string in the current line are counted, otherwise all occurrences of the string in the whole file are counted.
The parse pointer is not moved.
Text to info message
The text from the current parse pointer location to the end of the line is copied to the info message. If there is no text, the response code is set to 9 (Text for Info not found) and the execution is terminated.
The parse pointer is not moved.
Parsefile values and alarm limits
The parsefile job can enter the maintenance states Maintenance Ok or Maintenance Major, depending on the other alarm limits configured. E.g. if the following alarm limit is configured:
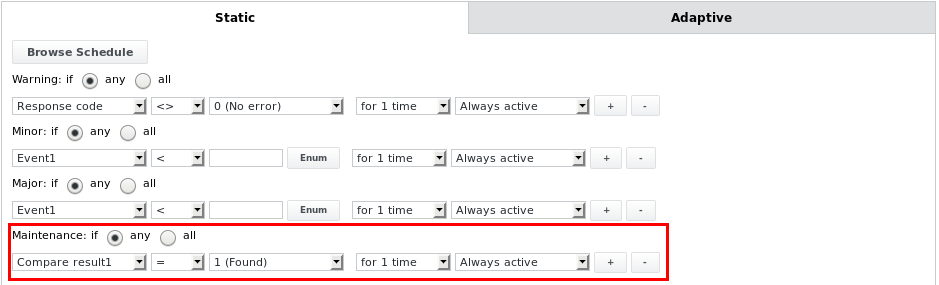
The job will enter the Maintenance OK state if the text comparison matched a certain string or expression and if it is otherwise in the state Ok. This can be used to put the job and its parent device (maintenance is propagated upwards from a job to its device) into maintenance mode depending on what is found when parsing a file that contains information on the maintenance state, e.g. from other monitoring systems like Nagios. All other alarm limits below can also be used in the Maintenance alarm limit.
Value / Alarm limit | Description |
|---|---|
Event1-X | Checks if an event has been triggered based on the Set Event sequence parameter above. |
Return value1-X | User-defined numeric value based on the Get value sequence parameter above. |
Rate value1-X | User-defined numeric rate value based on the Get rate value sequence parameter above. |
Diff value1-X | User-defined numeric diff value based on the Get diff value sequence parameter above. |
String value1-X | User-defined string value based on the Get string value sequence parameter above. |
Compare result1-X | User-defined value based on the Compare string value sequence parameter above. |
Match counter1-X | User-defined value based on the Count string matches sequence parameter above. |
Response code | 0 No error |
Error code | Generic job error code (see section Job error codes) |
Parsefile examples
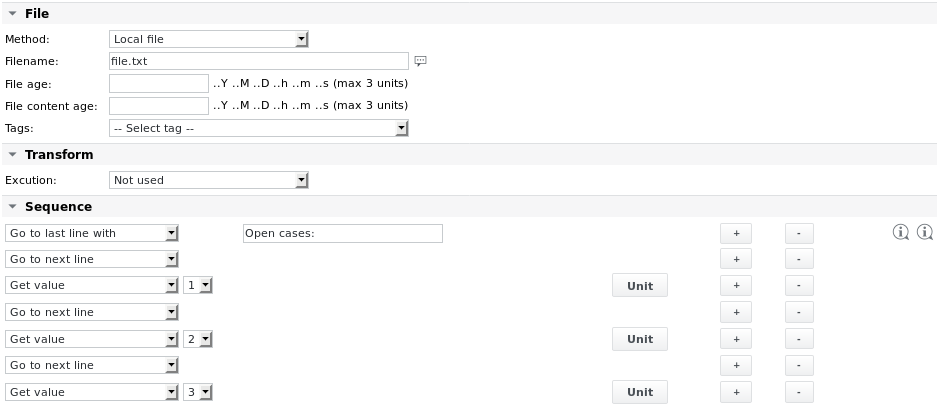
Example 1 - Parse a file file.txt which has the following content to read the 3 values in the last 3 lines:
11;OK;33;44.9888;MK;Duration (average): 203.6533s Open cases: 10 8 1
The job configuration looks as follows:
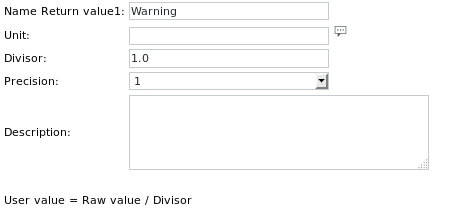
The Unit definition of the first Get value item is:
The other 2 Unit definitions are similar with the names Minor and Major respectively.
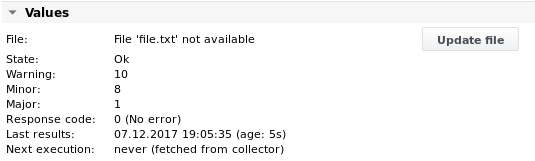
Output 1
Example 2 - Parse the same file.txt and extract values from its first line based on columns
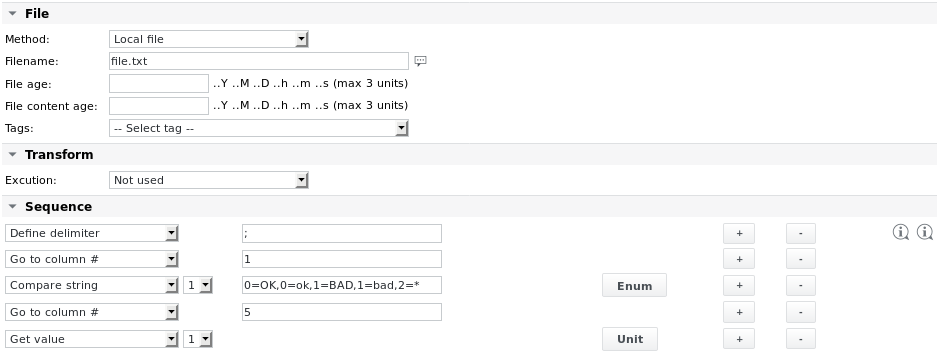
The Enum definition of the Compare string 1 item reads:

Whole text: 0=Status is good,1=Status is not so good,2=Status is unknown
The Unit definition for Get value 1 reads:
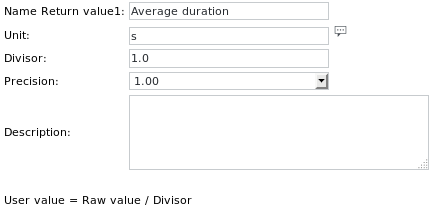
Notice the increased Precision, to be able to read floating-point numeric values.
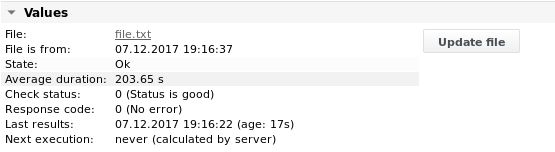
Output 2
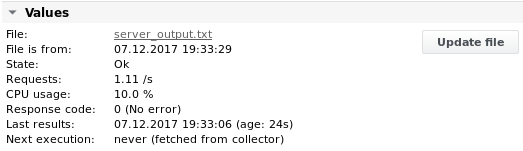
Example 3 - Search for a line containing the server name using variable tags. Stay on that line and get the values MeasurementValue1 and CPU_Usage
File contents are:
Timestamp=Fri Oct 31 09:55:20 CET 2017 ServerName=myserver01;MeasurementValue1=1.11;CPU_Usage=10%;EnumValue1=OK; ServerName=myserver02;MeasurementValue1=1.22;CPU_Usage=22%;EnumValue1=BAD;
The name of the device is myserver01.
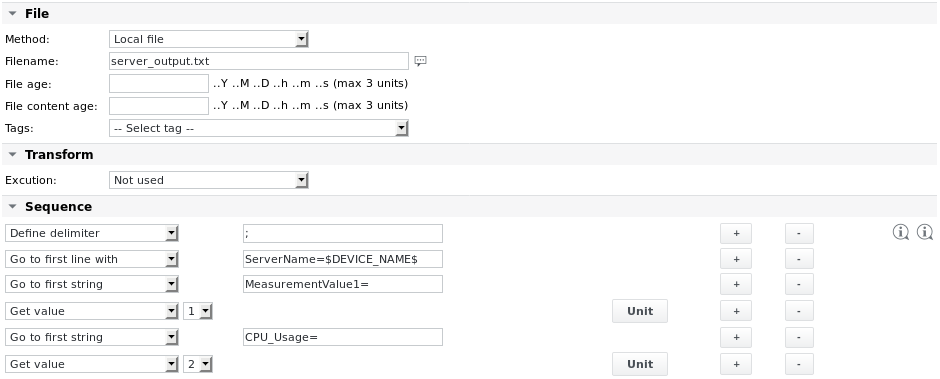
The Unit definitions are:
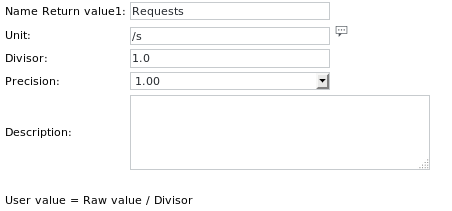
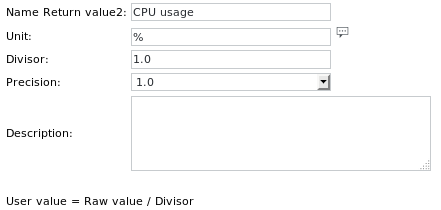
Using SKOOR Engine tags allows copying jobs to different devices and still have them working using the correct device name.
Output 3
Example 4 - Read a timestamp from a regularly generated file and read rate value to get the number of incoming and outgoing packets on a network interface
The file is generated regularly with the following content from an Execute job with the following Inline script contents:
date +%s%N | cut -c1-13 netstat -I=eth0
The first line prints the timestamp (seconds since 1.1.1970) in msec precision, the second line prints the receive/transmit statistics on the network interface eth0. The generated file is:
1512726065120 Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 5761332 0 0 0 2932100 0 0 0 BMRU
The rate values (incoming and outgoing packets) are independent of the execution intervals of both the execute job and the parsefile job. Usually one would put the execute job and the parse job below a Batch job and assign them an execution interval of No repetition, and only the Batch job would have an execution interval.
The parsefile job looks as follows:
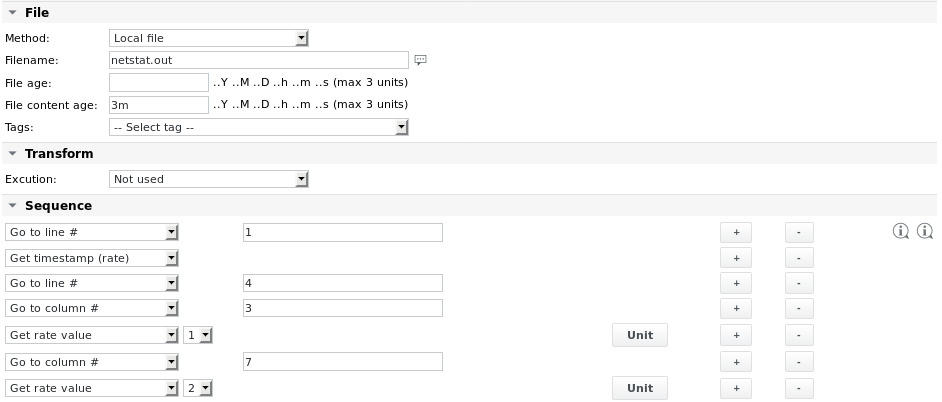
The Unit definitions are:
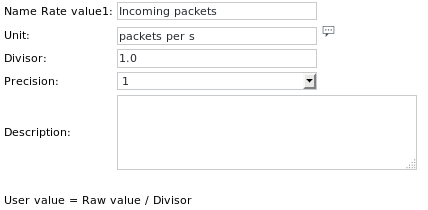
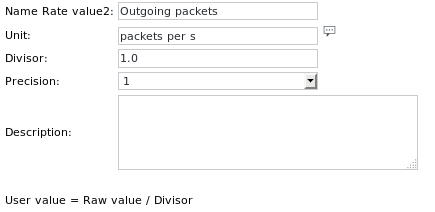
Output 4
The values are printed after the second execution of the job (the rate value needs a comparison with the previous measurement):
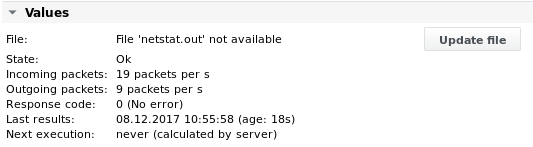
Example 5 - Generate events from parsed content
Read a file generated through an external job and search for certain strings. Generate an event1 when the string Error is found. Reset the event after a certain amount of time. Also generate an event2 if the string Process mysqld terminated is found. Reset the second event only if the string Process mysqld started is found further down in the file or during the next job execution.
In this example the first item in the parse sequence sets the Syslog mode parameter. This ensures that only new data in the file is parsed. The older parts of the file which have been parsed during the last job execution are no longer considered for subsequent job executions. If the first job run finds the string Error in the file it sets the Event1. If no new Error strings are found during the next 10 job executions (the job interval is set to 1 minute), the Event is reset.
The event mechanism allows the job to return to a OK state after a certain amount of time while still having the possibility to trigger an alarm email when a event is set.
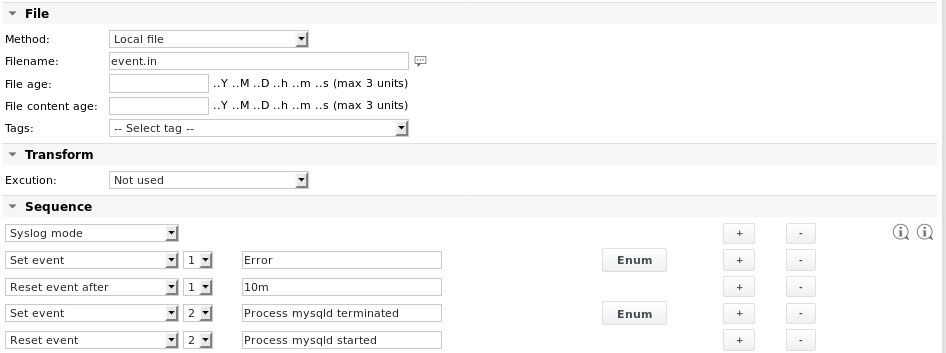
The Enum definitions are:


The alarm limits are configured as follows:
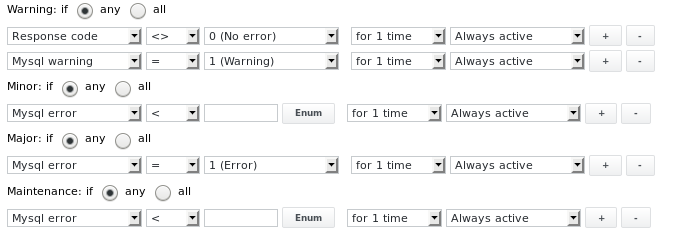
Output 5