Previsioni
Previsioni
Panoramica
Il modulo di previsione di SKOOR offre previsioni basate sull'apprendimento automatico (ML) delle tendenze future sui dati delle serie temporali. Sono disponibili quattro modelli:
Regressione lineare (vedi la documentazione ufficiale qui)
Tutti i modelli supportano serie indicizzate per data e ora provenienti direttamente da una DataSource o da un DataQuery di SKOOR.
Pagina delle previsioni
La pagina delle previsioni è suddivisa in due sezioni.
Pagina Generale
Questa sezione include le impostazioni delle previsioni.
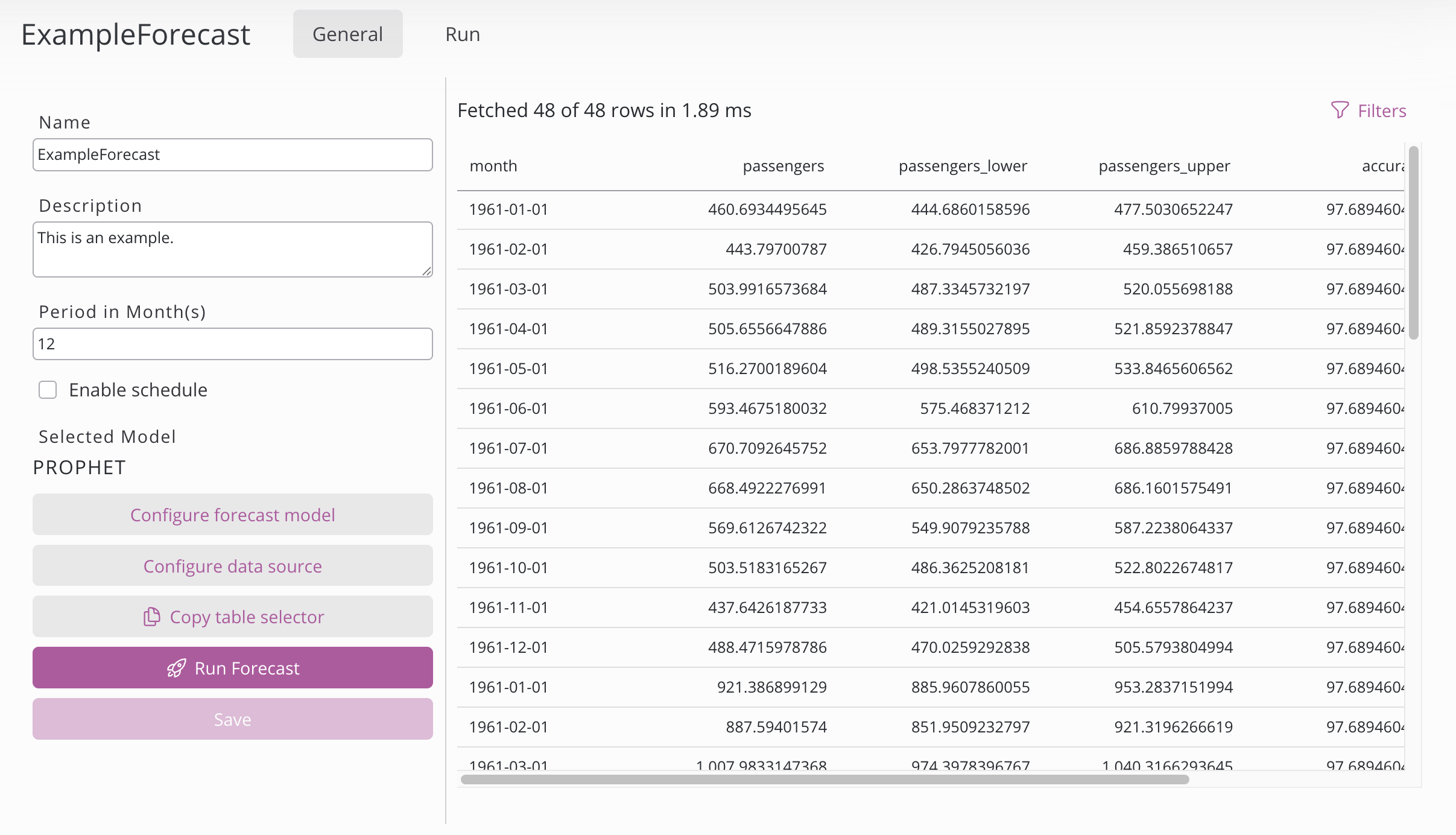
Sul lato sinistro:
Impostazione | Descrizione |
|---|---|
Nome | Nome della configurazione delle previsioni. |
Descrizione | Descrizione della configurazione di previsione. |
Periodo | Il periodo di previsione definisce fino a quanto in futuro un modello genera previsioni. Modificare l'unità del periodo nella configurazione della definizione dei dati. |
Abilita pianificazione | Scegliere innanzitutto un periodo (Anno, Mese, Settimana, Giorno, Ora o Minuto): a seconda della selezione effettuata, verranno visualizzati solo i campi pertinenti (Mesi, Giorni del mese, Giorni della settimana, Ore, Minuti). È possibile effettuare una selezione multipla; per eseguire il processo a intervalli regolari, impostare il Periodo e fare doppio clic sul numero desiderato. Esempio: ogni giorno alle 02:30 → Periodo "Giorno", Ora 2, Minuto 30. Esempio: ogni 10 minuti → Periodo "Ora", Minuto <fare doppio clic su 10> |
Modello selezionato | Il modello selezionato può essere modificato nella configurazione del modello di previsione. |
Configura il modello di previsione | Scegliere il modello per la previsione. |
Configurazione della definizione dei dati | Scegliere i dati per la previsione. |
Selettore "Copia tabella" | Pulsante per copiare la tabella contenente la previsione. |
Esegui previsione | Esegue una previsione con le impostazioni configurate. Lo stato e l'avanzamento sono visibili nella pagina di esecuzione. |
Salva | Salva la configurazione della previsione. Se l'opzione di ricerca degli iperparametri nel configuratore del modello è selezionata, al momento del salvataggio viene avviata automaticamente un'esecuzione della previsione. |
Sul lato destro è presente la panoramica dei dati di previsione in una tabella. Viene visualizzata solo se esiste già una previsione.
Pagina di esecuzione
Questa sezione è dedicata all'esecuzione e al monitoraggio delle esecuzioni delle previsioni. Offre il controllo sulla cronologia e consente di ottenere approfondimenti.
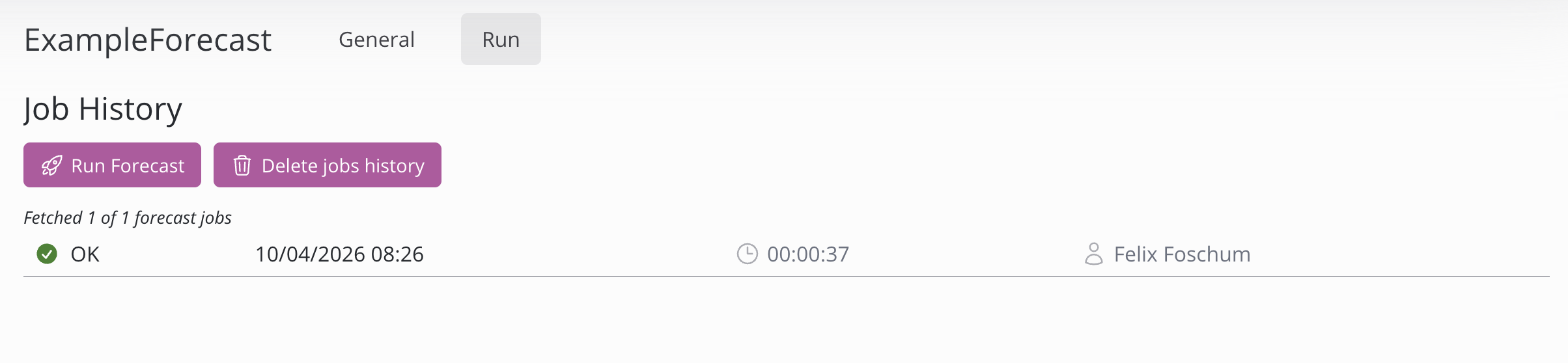
È possibile eseguire una previsione facendo clic sul pulsante "Esegui previsione". La cronologia completa delle esecuzioni può essere eliminata facendo clic sul pulsante "Elimina cronologia lavori". Si noti che tutte le tabelle create dalle previsioni verranno eliminate e, per recuperarle, sarà necessario eseguire nuovamente la previsione. Quando un’elaborazione è ancora in corso, può essere annullata cliccando sulla X rossa a destra dello stato visualizzato.
Cliccando su un'elaborazione, è possibile visualizzare l’output della console, lo stato di avanzamento, lo stato e ulteriori informazioni. Nell’output della console vengono riportati tutti i gruppi e la relativa accuratezza. L’accuratezza indicata è misurata con il WAPE (Weighted Absolute Percentage Error), è espressa in percentuale ed è calcolata in base alle prestazioni del modello sui dati storici.
Creazione di una previsione
È possibile creare una configurazione di previsione cliccando sul pulsante «+» sul lato sinistro e inserendo un nome oppure importando una previsione in formato JSON. Una volta creata la configurazione di previsione, è necessario impostare alcune opzioni nella pagina «Generale».
Configurazione del modello
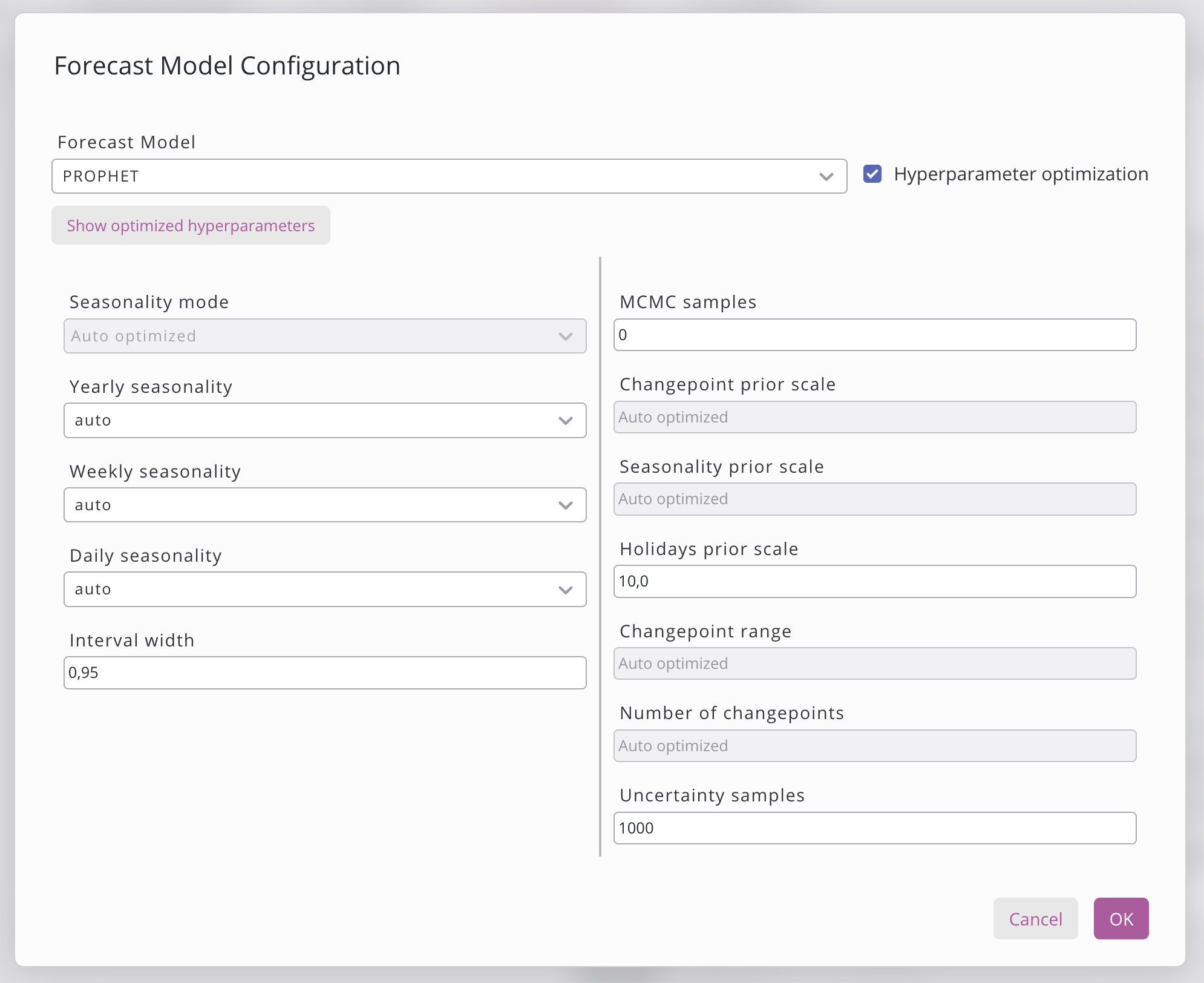
Cliccando sul pulsante «Configura modello di previsione» si apre una finestra di dialogo in cui è possibile scegliere il modello. Attualmente sono disponibili 4 diverse opzioni di modello, visibili qui sotto. Alcuni modelli dispongono di un pulsante di ottimizzazione degli iperparametri che consente al modello di testare varie combinazioni di iperparametri al fine di individuare quella ottimale. I vari iperparametri che è possibile impostare sono elencati sotto il modello. Se la ricerca degli iperparametri è già stata avviata, è possibile visualizzare e copiare gli iperparametri facendo clic sul pulsante "Mostra iperparametri ottimizzati".
Una volta terminata l’impostazione degli iperparametri, fare clic su «Salva» per salvare la configurazione del modello oppure su «Annulla» per annullare le modifiche.
Impostazioni | Descrizione |
|---|---|
Modello di previsione | Modello da utilizzare per le previsioni:
|
Ottimizzazione degli iperparametri | Quando è abilitata, il sistema ricerca automaticamente gli iperparametri ottimali testando varie impostazioni. Ciò aumenta il tempo di addestramento ma migliora l’accuratezza. |
Mostra iperparametri ottimizzati | Apre una finestra di dialogo che mostra gli iperparametri ottimali per gruppo o discriminatore individuati durante la ricerca degli iperparametri. |
L'ottimizzazione degli iperparametri è attualmente supportata in Prophet e XGBoost.
È possibile scegliere tra i seguenti modelli:
Prophet
Prophet è uno strumento open source basato sul Machine Learning sviluppato da Meta (ex Facebook) per la previsione di dati di serie temporali. È progettato per essere robusto in presenza di dati mancanti e di cambiamenti di tendenza, ed eccelle in particolare nella previsione di serie temporali con forte stagionalità. Prophet è in grado di gestire automaticamente gli effetti festivi e consente all’utente di impostare i propri iperparametri per renderlo ancora più preciso.
Prophet è l’opzione più utilizzata tra quelle disponibili perché richiede un tempo moderato per l’addestramento, ma fornisce costantemente i migliori risultati, rendendolo la scelta più conveniente nella maggior parte degli scenari. Prophet eccelle quando gli vengono forniti dati relativi a più stagioni in cui si verificano effetti stagionali ricorrenti, effetti festivi o cambiamenti irregolari di tendenza.
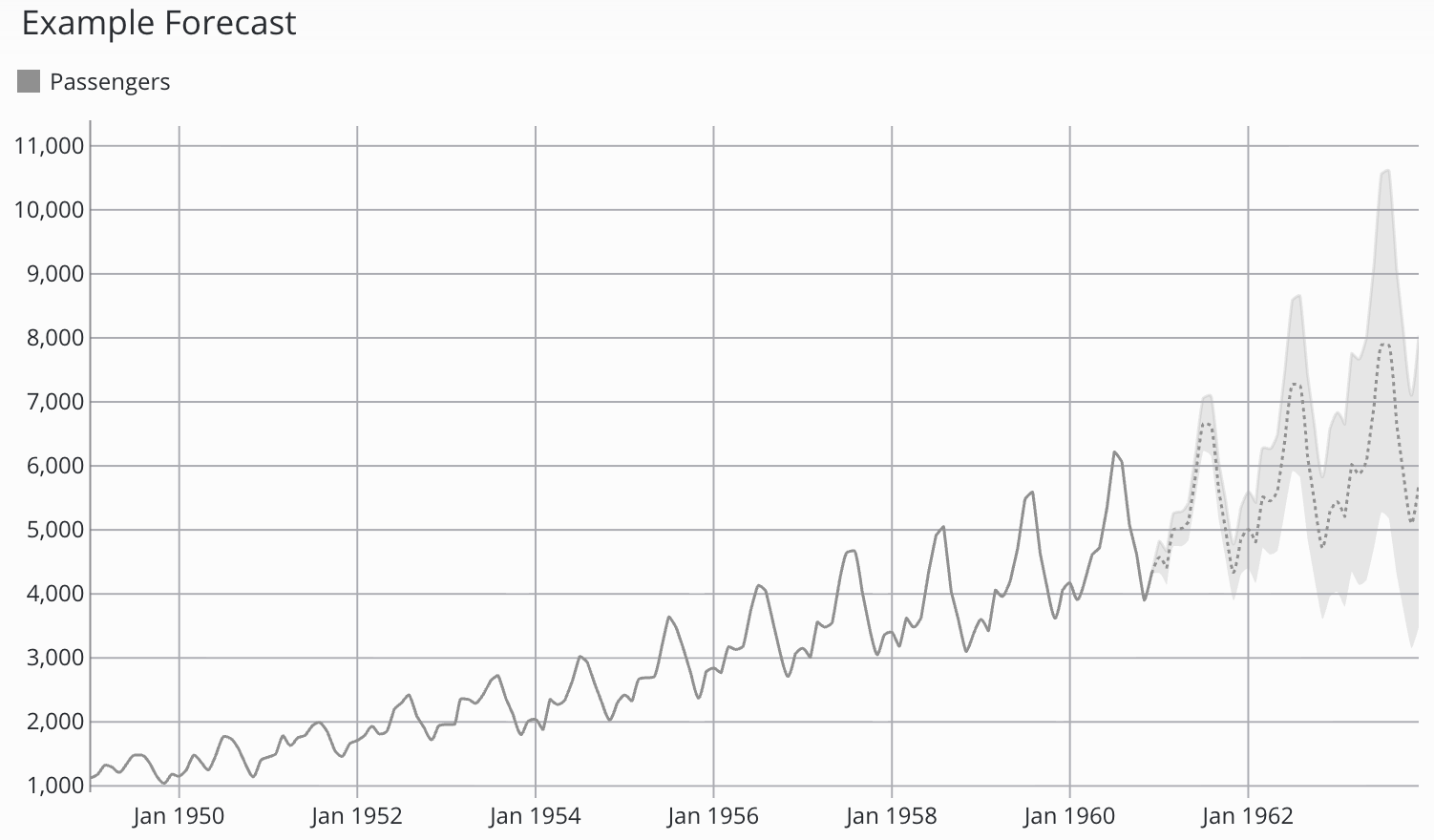
Se selezionato, il modello Prophet mostra anche le bande dell’intervallo di confidenza, che indicano il grado di certezza del modello nelle sue previsioni. Una volta visualizzata sulla dashboard, la banda dell’intervallo di confidenza appare in un colore più chiaro attorno alla previsione.
È possibile configurare le seguenti variabili:
Impostazione | Descrizione |
|---|---|
seasonality_mode | Determina se gli effetti stagionali vengono sommati o moltiplicati per la tendenza. Impostazione predefinita: |
yearly_seasonality | Abilita, disabilita o rileva automaticamente l'adattamento di un modello stagionale annuale. Impostazione predefinita: |
seasonalità_settimanale | Abilita, disabilita o rileva automaticamente l'adattamento di un modello stagionale settimanale. Impostazione predefinita: |
daily_seasonality | Abilita, disabilita o rileva automaticamente l'adattamento di un modello stagionale giornaliero. Impostazione predefinita: |
interval_width | Ampiezza dell’intervallo di incertezza restituito con ciascuna previsione. Impostazione predefinita: |
mcmc_samples | Numero di campioni MCMC per l’inferenza bayesiana completa; se impostato a 0, viene utilizzata invece la stima MAP. Impostazione predefinita: |
changepoint_prior_scale | Controlla la flessibilità della tendenza nei punti di cambiamento; valori più alti consentono cambiamenti di tendenza più marcati. Impostazione predefinita: |
seasonality_prior_scale | Intensità di regolarizzazione per le componenti stagionali; valori più elevati consentono oscillazioni stagionali più ampie. Impostazione predefinita: |
holidays_prior_scale | Controlla l’entità degli effetti delle festività sulla previsione. Valore predefinito: |
changepoint_range | Frazione della cronologia di addestramento in cui è consentito il verificarsi di punti di cambiamento di tendenza. Impostazione predefinita: |
n_changepoints | Numero di potenziali punti di cambiamento di tendenza inseriti automaticamente nel periodo di addestramento. Impostazione predefinita: |
uncertainty_samples | Numero di estrazioni a posteriori utilizzate per stimare gli intervalli di incertezza delle previsioni. Impostazione predefinita: |
SARIMAX
SARIMAX (Seasonal Autoregressive Integrated Moving Average with Exogenous Regressors) è un modello statistico utilizzato per prevedere valori futuri sulla base dei dati passati. Gestisce sia le tendenze che i modelli stagionali. Si tratta dell’estensione del modello ARIMA con l’aggiunta di componenti stagionali.
Il modello SARIMAX è particolarmente efficace quando i dati generati sono stabili e coerenti e quando si preferisce un modello statistico a un modello di apprendimento automatico.
Nel modello SARIMAX non sono presenti variabili che possano essere regolate dall’utente.
Regressione lineare
La regressione lineare viene utilizzata per prevedere le tendenze esclusivamente adattando una linea retta ai dati di addestramento ed estendendo tale linea nel futuro. Si tratta di uno strumento potente per prevedere le tendenze future in qualsiasi serie temporale.
La regressione lineare è particolarmente indicata quando i dati sottostanti mostrano un andamento lineare chiaro e coerente, con stagionalità o rumore minimi.
Nel modello di regressione lineare non sono presenti variabili che possano essere regolate dall’utente.
XGBoost
Il modello XGBoost utilizza alberi decisionali potenziati dal gradiente per una previsione diretta in più fasi. Prima dell’addestramento, applica un’ampia ingegneria delle caratteristiche alla serie temporale di input, estraendo caratteristiche di ritardo, statistiche mobili e caratteristiche basate sul calendario, per poi prevedere ogni punto futuro in modo indipendente.
XGBoost funziona al meglio con dati complessi e non lineari. Può raggiungere una buona accuratezza, ma richiede tempo per l’addestramento e, in alcuni casi, i dati devono essere pre-elaborati separatamente in anticipo.
È possibile configurare le seguenti variabili:
Impostazione | Descrizione |
|---|---|
obiettivo | Funzione di perdita utilizzata durante l'addestramento; determina quale metrica di errore il modello ottimizza. Impostazione predefinita: |
quantile_alpha | Livello quantile target quando si utilizza la regressione quantile come obiettivo. Impostazione predefinita: |
n_estimators | Numero di alberi di boosting da costruire; un numero maggiore di alberi aumenta la capacità ma comporta il rischio di overfitting. Impostazione predefinita: |
learning_rate | Riduzione dell’ampiezza del passo applicata dopo ogni albero per prevenire l’overfitting. Impostazione predefinita: |
max_depth | Profondità massima di ciascun albero; controlla la complessità del modello e l’ordine di interazione. Predefinito: |
min_child_weight | Somma minima dei pesi delle istanze richiesta per creare un nodo foglia. Impostazione predefinita: |
gamma | Riduzione minima della perdita richiesta per dividere un nodo; valori più alti rendono il modello più conservativo. Predefinito: |
subsample | Frazione di righe di addestramento campionate per albero, utilizzata per ridurre l’overfitting. Impostazione predefinita: |
colsample_bytree | Frazione di caratteristiche selezionate casualmente durante la costruzione di ciascun albero. Impostazione predefinita: |
reg_alpha | Termine di regolarizzazione L1 sui pesi delle foglie; favorisce soluzioni sparse. Valore predefinito: |
reg_lambda | Termine di regolarizzazione L2 sui pesi delle foglie; penalizza i valori di peso elevati. Impostazione predefinita: |
Origine dati
La finestra di configurazione della fonte dati consente di specificare i dati utilizzati per addestrare il modello.
La fonte dei dati può essere selezionata a sinistra. Esistono due tipi di fonte di dati: una fonte di dati dal proprio database SKOOR o una query di dati dalla scheda "Data Query". Quando si seleziona l’origine dati, sono richieste ulteriori scelte che possono essere impostate nella finestra, quali l’origine dati, la tabella e le colonne. Quando si seleziona l’opzione «query dati», è necessario impostare la query dati, nonché le colonne di tale query.
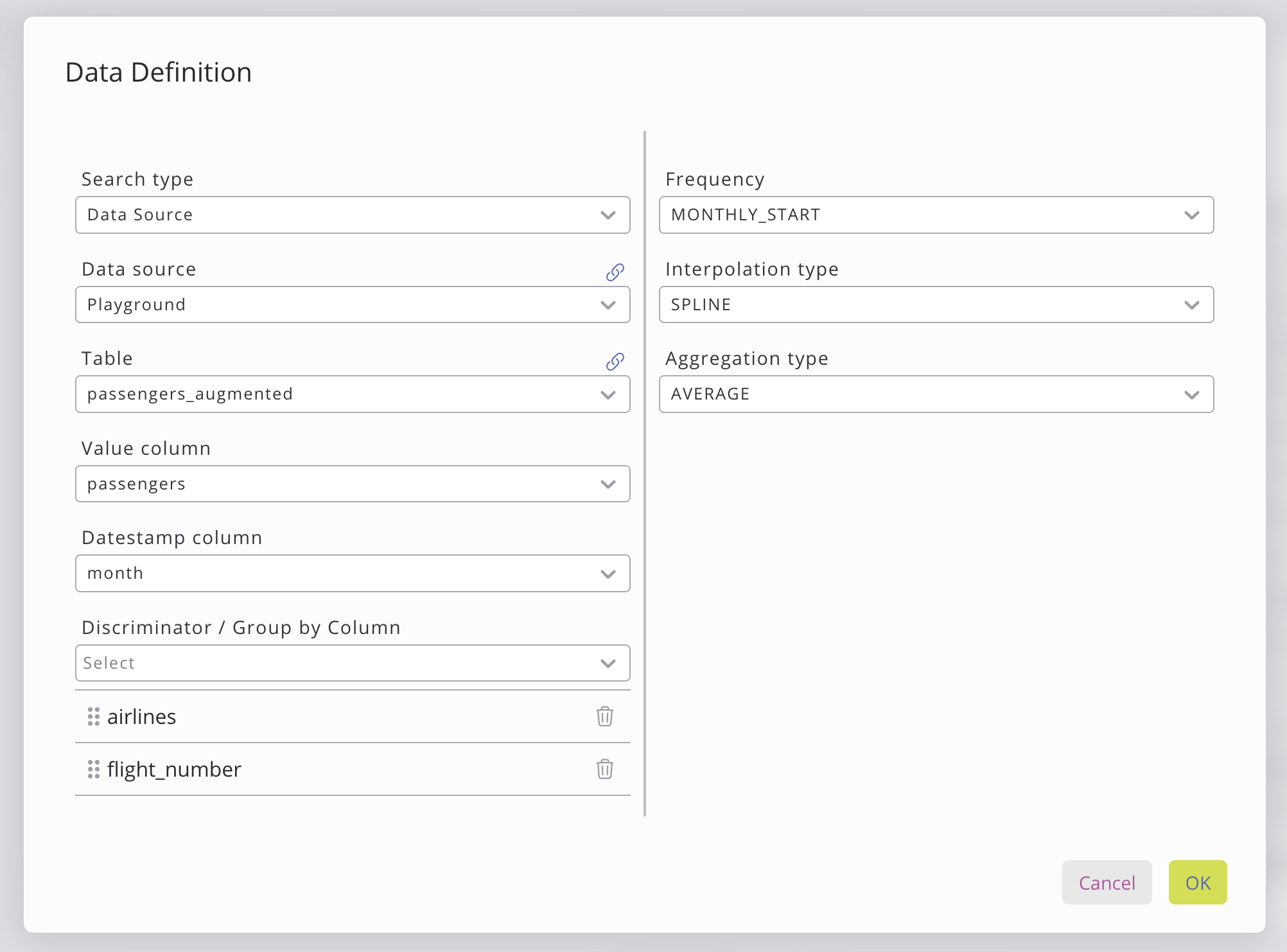
Le colonne "Valore", "Data e ora" e "Discriminatore" possono essere selezionate facendo clic sul menu a tendina. Il menu a tendina mostrerà automaticamente le colonne che soddisfano i requisiti. È necessario scegliere le seguenti colonne:
Impostazione | Descrizione |
|---|---|
Colonna del valore | Deve contenere valori numerici associati a ciascun timestamp. |
Colonna "Data" | I dati devono utilizzare il formato di timestamp AAAA-MM-GG HH:mm e ogni gruppo di dati deve avere timestamp univoci per gruppo (gruppi definiti dalle colonne discriminanti o dalla struttura intrinseca dei dati). |
Colonne discriminanti | Colonne opzionali utilizzate per definire il raggruppamento e la gerarchia (ad es. paese → stato → città). Non vi sono requisiti rigorosi per i dati, ma l’ordine delle colonne è importante, poiché ogni livello affina ulteriormente il raggruppamento. |
Sul lato destro della finestra dei dati è possibile selezionare ulteriori operazioni di pre-elaborazione dei dati.
Impostazioni | Descrizione |
|---|---|
Frequenza | Imposta la risoluzione di output della previsione. Maggiori informazioni. |
Tipo di interpolazione | Definisce come vengono inseriti i timestamp mancanti. Maggiori informazioni. |
Tipo di aggregazione | Controlla come vengono combinati più valori all'interno di un periodo. Maggiori informazioni. |
Fuso orario | Reimposta il timestamp nel fuso orario specificato. |
Frequenza
La frequenza determina l'output della previsione. È possibile scegliere tra le seguenti frequenze:
Impostazione | Descrizione |
|---|---|
SECONDLY | Risultati delle previsioni con risoluzione al secondo. |
MINUTELY | Risultati delle previsioni con risoluzione al minuto. |
OGNI ORA | Risultati delle previsioni con risoluzione oraria. |
GIORNALIERA | Risultati delle previsioni con risoluzione giornaliera. |
SETTIMANALE_DOM | Risultati delle previsioni con risoluzione settimanale; la settimana inizia la domenica. |
SETTIMANALE_LUN | Risultati delle previsioni con risoluzione settimanale; la settimana inizia il lunedì. |
WEEKLY_TUE | Risultati delle previsioni con risoluzione settimanale; la settimana inizia il martedì. |
WEEKLY_WED | Risultati delle previsioni con risoluzione settimanale; la settimana inizia il mercoledì. |
WEEKLY_THU | Risultati delle previsioni con risoluzione settimanale, la settimana inizia il giovedì. |
WEEKLY_FRI | Risultati delle previsioni con risoluzione settimanale; la settimana inizia il venerdì. |
WEEKLY_SAT | Risultati delle previsioni con risoluzione settimanale, la settimana inizia il sabato. |
MONTHLY_END | Risultati delle previsioni con risoluzione mensile, riferiti all'ultimo giorno del mese. |
MONTHLY_START | Risultati delle previsioni con risoluzione mensile, con riferimento al primo giorno del mese. |
QUARTERLY_END | Risultati delle previsioni con risoluzione trimestrale, riferiti all'ultimo giorno del trimestre. |
QUARTERLY_START | Risultati delle previsioni con risoluzione trimestrale, con riferimento al primo giorno del trimestre. |
YEARLY_END | Risultati delle previsioni con risoluzione annuale, riferiti all'ultimo giorno dell'anno. |
YEARLY_START | Risultati delle previsioni con risoluzione annuale, con riferimento al primo giorno dell’anno. |
Internamente, la serie di dati fornita viene interpolata o aggregata alla frequenza impostata utilizzando il tipo di interpolazione e/o il tipo di aggregazione. Si noti che se i dati presentano date mancanti o un numero di dati eccessivo rispetto alla frequenza, l'interpolazione e/o l'aggregazione selezionate vengono applicate automaticamente per garantire una previsione fluida.
Tipi di interpolazione:
Impostazione | Descrizione |
|---|---|
Nessuna | Non viene applicata alcuna interpolazione; i dati vengono elaborati così come sono. |
Lineare | Riempie i vuoti tracciando una linea retta tra i valori noti. |
In avanti | Riempie i vuoti in avanti utilizzando l'ultimo valore noto (riempimento in avanti). |
Ultimo | Riempie gli spazi vuoti all'indietro utilizzando il valore noto successivo (riempimento all'indietro). |
Spline | Riempie i valori mancanti utilizzando una curva cubica liscia adattata ai valori noti. |
Tipi di aggregazione:
Impostazione | Descrizione |
|---|---|
Nessuna | Non viene applicata alcuna aggregazione, i dati vengono elaborati così come sono. |
Somma | Somma tutti i valori all'interno di ciascun periodo. |
Media | Calcola la media di tutti i valori all'interno di ciascun periodo. |
Mediana | Restituisce il valore centrale di tutti i valori all'interno di ciascun periodo. |
Conteggio | Conta il numero di valori non nulli all'interno di ciascun periodo. |
Min | Restituisce il valore più piccolo all'interno di ciascun periodo. |
Max | Restituisce il valore più grande all'interno di ciascun periodo. |
Primo | Restituisce il primo valore all'interno di ciascun periodo. |
Last | Restituisce l'ultimo valore all'interno di ciascun periodo. |
STD | Calcola la deviazione standard di tutti i valori all'interno di ciascun periodo. |
Fuso orario
Internamente, tutti i timestamp vengono reimpostati nel fuso orario impostato dall'utente.
Autorizzazioni
Sola lettura
Leggere i risultati delle previsioni
Ricerca delle configurazioni di previsione in base alla definizione dei valori
Modifica
Tutto ciò che la modalità "Sola lettura" può fare
Elenca tutte le configurazioni di previsione (solo vista semplice)
Editor dati
Tutto ciò che l'Editor può fare
Diritti completi (crea, leggi, aggiorna, elimina) sulle configurazioni di previsione e sui gruppi
Avviare, visualizzare e annullare i processi di previsione
Esportazione/importazione delle configurazioni
Amministratore
Tutto ciò che Dataeditor può fare
Eliminare la cronologia dei processi
Visualizzazione delle previsioni su una dashboard
Utilizzo del widget di previsione predefinito
SKOOR semplifica l'accesso alle previsioni grazie all'introduzione di un pulsante nel widget dei grafici. È sufficiente creare un widget grafico sulla dashboard, impostare il tipo di grafico su "Misto" e configurare le stesse definizioni dei dati presenti nella configurazione delle previsioni. Dopo aver impostato la fonte dati, clicca su "Sincronizza colonne" nella sezione "Colonne" in basso a destra nella finestra di dialogo di modifica del widget oppure aggiungi manualmente la colonna per cui è stata effettuata la previsione. Quindi clicca su quella colonna e spunta la casella "Mostra previsione". Seleziona la configurazione di previsione corrispondente dal menu a tendina, quindi applica. A questo punto, l’anteprima dovrebbe già mostrare i dati storici con la previsione corrispondente.
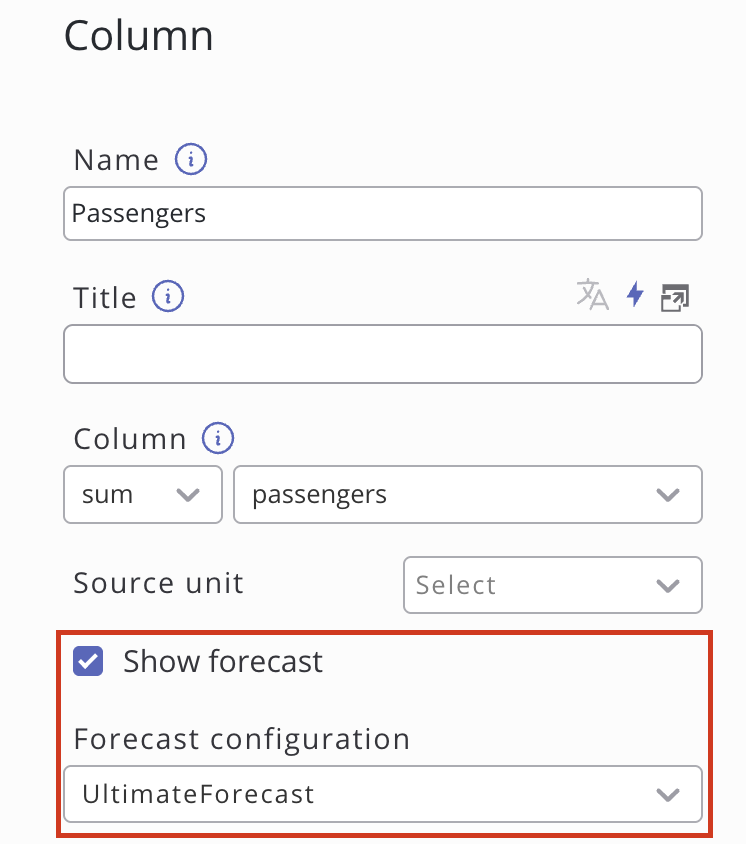
Utilizzo di una query dati personalizzata
La tabella contenente i risultati delle previsioni può essere copiata negli appunti semplicemente facendo clic sul selettore "Copia tabella" nella pagina "Generale" della configurazione delle previsioni. Utilizzando questa tabella, è possibile accedere ai dati delle previsioni e scrivere una propria query di dati, ad esempio in SKOOR Studio. Si noti che vi sono differenze nelle colonne della tabella, come descritto di seguito:
Prophet
(con lo stesso nome della colonna del valore di input)
colonna del timbro data (con lo stesso nome della colonna del timbro data di input)
valore di confidenza inferiore (con lo stesso nome della colonna dei valori di input, ma con “_lower” alla fine)
valore di confidenza superiore (con lo stesso nome della colonna del valore di input, ma con “_upper” alla fine)
accuratezza
colonne discriminanti (Stesso numero di colonne del numero di colonne discriminanti specificato. Denominate come le colonne discriminanti di input.)
Regressione lineare
colonna dei valori (con lo stesso nome della colonna dei valori di input).
colonna del timbro data (Con lo stesso nome della colonna del timbro data in ingresso.)
accuratezza
colonne discriminanti (Stesso numero di colonne del numero di colonne discriminanti specificato. Hanno lo stesso nome delle colonne discriminanti di input.)
SARIMAX
colonna dei valori (con lo stesso nome della colonna dei valori in ingresso)
colonna data e ora (con lo stesso nome della colonna data e ora in ingresso)
accuratezza
colonne discriminanti (Stesso numero di colonne del numero di colonne discriminanti specificato. Denominate come le colonne discriminanti di input.)
XGBoost
colonna del valore (con lo stesso nome della colonna del valore in ingresso)
colonna del timbro data (con lo stesso nome della colonna del timbro data in ingresso)
accuratezza
colonne discriminanti (Lo stesso numero di colonne corrispondente al numero di colonne discriminanti specificate. Con lo stesso nome delle colonne discriminanti di input.)