Prévisions
Prévisions
Présentation
Le module de prévision de SKOOR propose des prévisions basées sur l'apprentissage automatique (ML) des tendances futures à partir de données de séries chronologiques. Quatre modèles sont disponibles :
Régression linéaire (voir la documentation officielle ici)
Tous les modèles prennent en charge les séries indexées par date et heure provenant directement d'une source de données SKOOR (DataSource) ou d'une requête de données (DataQuery).
Page de prévision
La page de prévision est divisée en deux sections.
Page « Général »
Cette section comprend les paramètres des prévisions.
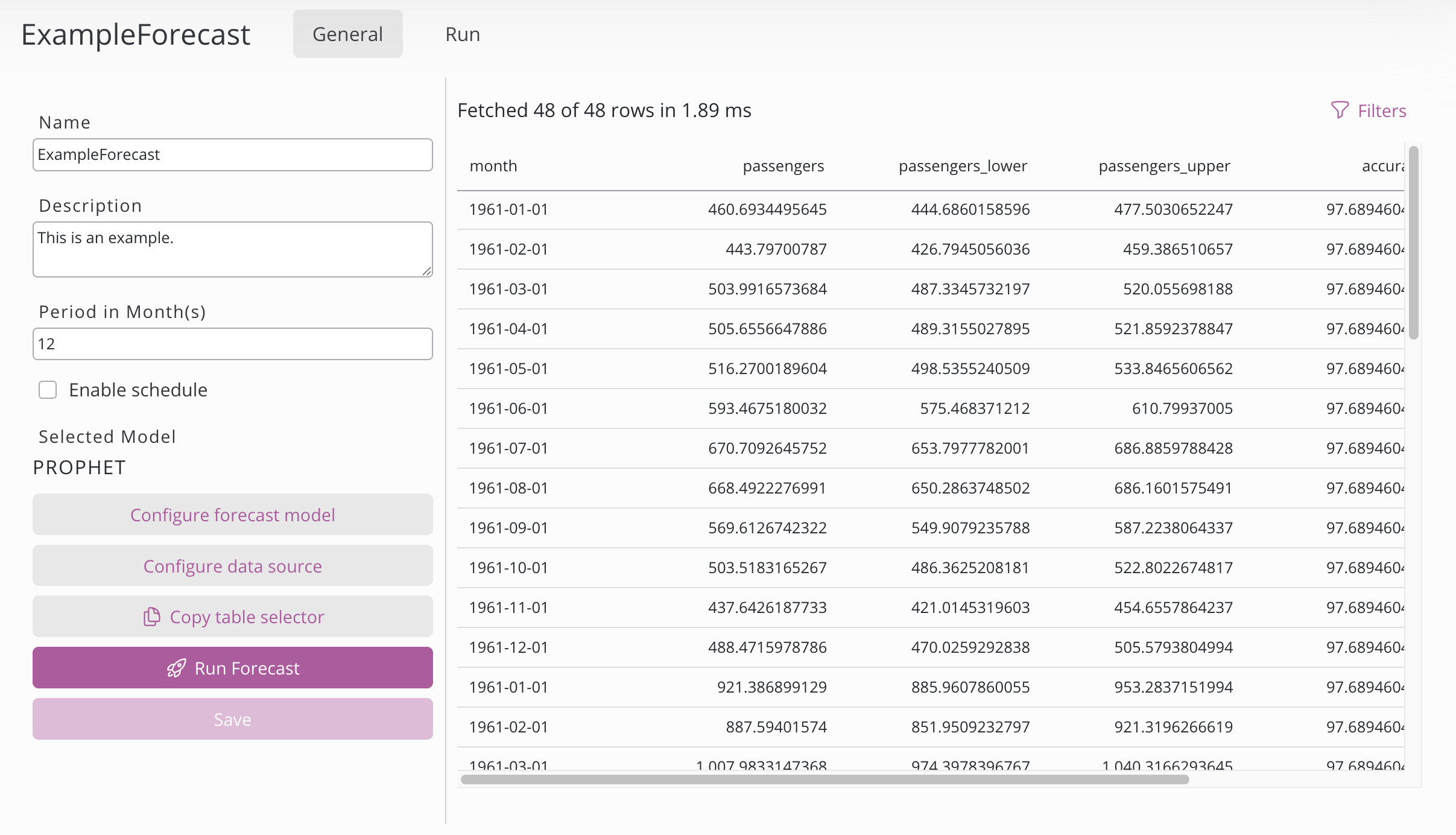
À gauche :
Paramètre | Description |
|---|---|
Nom | Nom de la configuration de prévision. |
Description | Description de la configuration de prévision. |
Période | La période de prévision définit jusqu'à quand dans le futur un modèle génère des prévisions. Modifiez l'unité de la période dans la configuration de définition des données. |
Activer la planification | Commencez par choisir une période (Année, Mois, Semaine, Jour, Heure ou Minute) – en fonction de votre sélection, seuls les champs pertinents s'affichent (Mois, Jours du mois, Jours de la semaine, Heures, Minutes). La sélection multiple est possible et, pour exécuter le processus à intervalles réguliers, définissez la Période puis double-cliquez sur le nombre souhaité. Exemple : tous les jours à 02h30 → Période « Jour », Heure 2, Minute 30. Exemple : toutes les 10 minutes → Période « Heure », Minute <double-clic sur 10> |
Modèle sélectionné | Le modèle sélectionné peut être modifié dans la configuration du modèle de prévision. |
Configurer le modèle de prévision | Choisissez le modèle de prévision. |
Configurer la définition des données | Sélectionnez les données à utiliser pour la prévision. |
Sélecteur de copie de table | Bouton permettant de copier la table contenant les prévisions. |
Lancer la prévision | Exécute une prévision avec les paramètres configurés. L'état et la progression sont visibles sur la page d'exécution. |
Enregistrer | Enregistre la configuration de la prévision. Si l'option de recherche d'hyperparamètres dans le configurateur de modèle est cochée, une prévision est automatiquement lancée lors de l'enregistrement. |
À droite se trouve un aperçu des données de prévision sous forme de tableau. Il n'apparaît que si une prévision existe déjà.
Page d'exécution
Cette section permet d'exécuter et de surveiller les exécutions de la prévision. Elle offre un contrôle sur l'historique et permet d'obtenir des informations utiles.
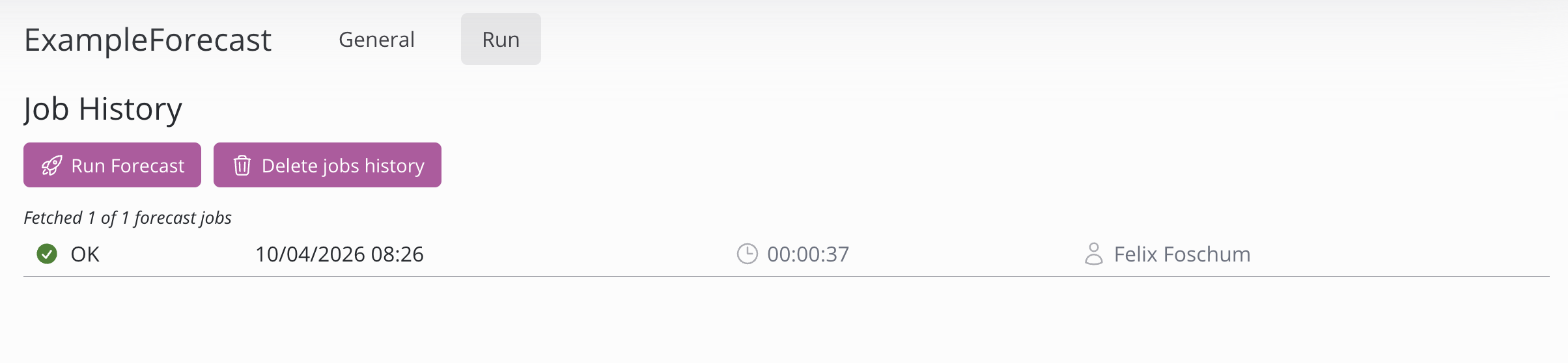
Pour lancer une prévision, cliquez sur le bouton « Lancer la prévision ». L'historique complet des exécutions peut être supprimé en cliquant sur le bouton « Supprimer l'historique des tâches ». Notez que tous les tableaux créés par les prévisions seront supprimés et que, pour les récupérer, vous devrez relancer la prévision. Lorsqu’une tâche est encore en cours d’exécution, elle peut être annulée en cliquant sur le X rouge situé à droite de l’état affiché.
En cliquant sur une tâche, vous pouvez consulter la sortie de la console, la progression, le statut et des informations complémentaires. Dans la sortie de la console, chaque groupe et sa précision sont affichés. La précision indiquée est mesurée à l’aide du WAPE (Weighted Absolute Percentage Error, erreur absolue pondérée en pourcentage) ; elle est exprimée en pourcentage et calculée à partir des performances du modèle sur les données historiques.
Création d’une prévision
Une configuration de prévision peut être créée soit en cliquant sur le bouton « Plus » situé à gauche et en saisissant un nom, soit en important une prévision au format JSON. Une fois la configuration de prévision créée, quelques paramètres doivent être définis sur la page « Général ».
Configuration du modèle
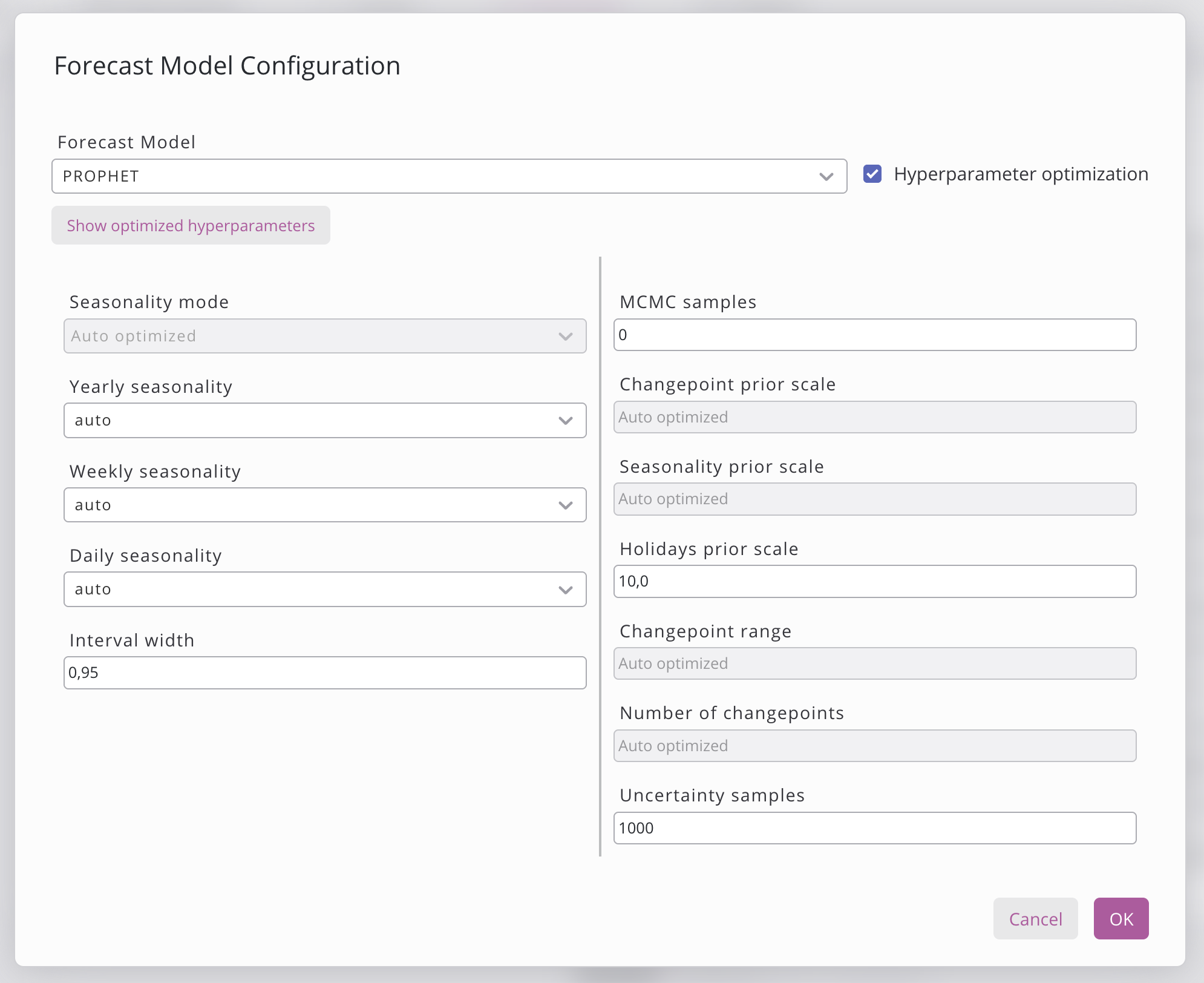
Cliquer sur le bouton « Configurer le modèle de prévision » ouvre une boîte de dialogue dans laquelle le modèle peut être sélectionné. Actuellement, quatre options de modèle différentes sont disponibles, comme indiqué ci-dessous. Certains modèles disposent d’un bouton « Optimisation des hyperparamètres » qui permet au modèle de tester diverses combinaisons d’hyperparamètres afin de déterminer la meilleure. Les différents hyperparamètres pouvant être définis sont répertoriés sous le modèle. Si la recherche d’hyperparamètres a déjà été lancée, vous pouvez afficher et copier les hyperparamètres en cliquant sur le bouton « Afficher les hyperparamètres optimisés ».
Une fois que vous avez terminé de définir les hyperparamètres, cliquez sur « Enregistrer » pour enregistrer la configuration du modèle ou sur « Annuler » pour annuler les modifications.
Paramètres | Description |
|---|---|
Modèle de prévision | Modèle à utiliser pour les prévisions :
|
Optimisation des hyperparamètres | Lorsqu’elle est activée, le système recherche automatiquement les hyperparamètres optimaux en testant différents réglages. Cela augmente le temps d’entraînement mais améliore la précision. |
Afficher les hyperparamètres optimisés | Ouvre une boîte de dialogue affichant les hyperparamètres optimaux par groupe ou par discriminateur identifiés lors de la recherche d’hyperparamètres. |
L'optimisation des hyperparamètres est actuellement prise en charge dans Prophet et XGBoost.
Les modèles suivants sont disponibles :
Prophet
Prophet est un outil open source basé sur l'apprentissage automatique, développé par Meta (anciennement Facebook) pour la prévision de données de séries chronologiques. Il est conçu pour résister aux données manquantes et aux changements de tendance, et excelle particulièrement dans la prévision de séries chronologiques présentant une forte saisonnalité. Prophet peut gérer automatiquement les effets liés aux jours fériés et permet à l’utilisateur de définir ses propres hyperparamètres pour le rendre encore plus précis.
Prophet est l’option la plus largement utilisée parmi celles disponibles, car son apprentissage ne prend qu’un temps modéré, mais il fournit systématiquement les meilleurs résultats, ce qui en fait le choix le plus rentable dans la plupart des scénarios. Prophet excelle lorsqu’on lui fournit plusieurs saisons de données présentant des effets saisonniers récurrents, des effets liés aux jours fériés ou des changements de tendance irréguliers.
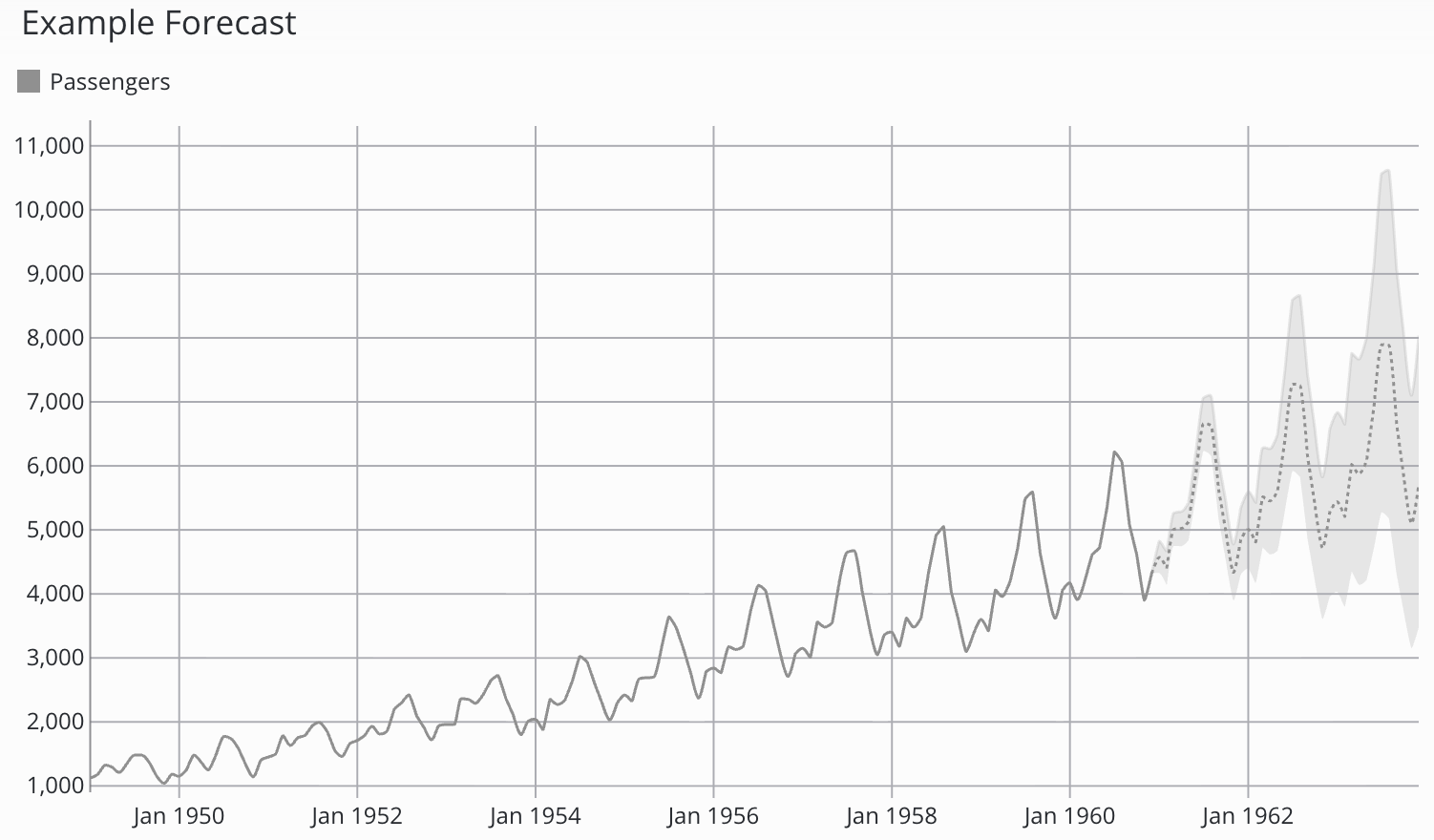
Lorsqu’il est sélectionné, le modèle Prophet affiche également des intervalles de confiance, qui indiquent le degré de certitude du modèle quant à ses prévisions. Lorsqu’il est visualisé sur le tableau de bord, l’intervalle de confiance apparaît dans une couleur plus claire autour de la prévision.
Les variables suivantes peuvent être configurées :
Paramètre | Description |
|---|---|
seasonality_mode | Détermine si les effets saisonniers sont additionnés ou multipliés par la tendance. Par défaut : « |
yearly_seasonality | Active, désactive ou détecte automatiquement l'ajustement d'un modèle saisonnier annuel. Valeur par défaut : |
weekly_seasonality | Active, désactive ou détecte automatiquement l'ajustement d'un modèle saisonnier hebdomadaire. Par défaut : |
daily_seasonality | Active, désactive ou détecte automatiquement l'ajustement d'un modèle saisonnier quotidien. Par défaut : |
interval_width | Largeur de l'intervalle d'incertitude renvoyé avec chaque prévision. Valeur par défaut : |
mcmc_samples | Nombre d’échantillons MCMC pour une inférence bayésienne complète ; la valeur 0 utilise à la place l’estimation MAP. Par défaut : |
changepoint_prior_scale | Contrôle la flexibilité de la tendance aux points de changement ; des valeurs plus élevées permettent des changements de tendance plus marqués. Par défaut : |
seasonality_prior_scale | Force de régularisation pour les composantes saisonnières ; des valeurs plus élevées permettent des fluctuations saisonnières plus importantes. Par défaut : |
holidays_prior_scale | Contrôle l’ampleur des effets des jours fériés sur les prévisions. Valeur par défaut : |
changepoint_range | Fraction de l'historique d'apprentissage dans laquelle des points de changement de tendance sont autorisés. Valeur par défaut : |
n_changepoints | Nombre de points de changement de tendance potentiels automatiquement placés dans la période d'apprentissage. Par défaut : |
uncertainty_samples | Nombre d’échantillons a posteriori utilisés pour estimer les intervalles d’incertitude des prévisions. Valeur par défaut : |
SARIMAX
SARIMAX (moyenne mobile intégrée autorégressive saisonnière avec régresseurs exogènes) est un modèle statistique utilisé pour prédire des valeurs futures à partir de données passées. Il prend en compte à la fois les tendances et les variations saisonnières. Il s’agit d’une extension du modèle ARIMA par l’ajout de composantes saisonnières.
Le modèle SARIMAX est particulièrement adapté lorsque les données générées sont stables et cohérentes, et lorsqu’un modèle statistique est préféré à un modèle d’apprentissage automatique.
Le modèle SARIMAX ne comporte aucune variable pouvant être ajustée par l'utilisateur.
Régression linéaire
La régression linéaire sert à prédire les tendances uniquement en ajustant une droite aux données d’apprentissage et en prolongeant cette droite dans le futur. C’est un outil puissant pour prédire les tendances futures de n’importe quelle série chronologique.
La régression linéaire est particulièrement indiquée lorsque les données sous-jacentes présentent une tendance linéaire claire et cohérente, avec un minimum de saisonnalité ou de bruit.
Le modèle de régression linéaire ne comporte aucune variable pouvant être ajustée par l’utilisateur.
XGBoost
Le modèle XGBoost utilise des arbres de décision à gradient boosté pour effectuer des prévisions directes en plusieurs étapes. Avant l'apprentissage, il applique un traitement approfondi des caractéristiques aux séries chronologiques d'entrée, en extrayant des caractéristiques de décalage, des statistiques glissantes et des caractéristiques basées sur le calendrier, puis prédit chaque point futur de manière indépendante.
XGBoost fonctionne particulièrement bien avec des données complexes et non linéaires. Il peut atteindre une bonne précision, mais son apprentissage prend du temps et, dans certains cas, les données doivent être prétraitées séparément au préalable.
Les variables suivantes peuvent être configurées :
Paramètre | Description |
|---|---|
objectif | Fonction de perte utilisée pendant l'entraînement ; détermine la métrique d'erreur que le modèle optimise. Par défaut : |
quantile_alpha | Niveau de quantile cible lorsque la régression quantile est utilisée comme objectif. Valeur par défaut : |
n_estimators | Nombre d’arbres de boosting à construire ; un nombre plus élevé d’arbres augmente la capacité mais présente un risque de surapprentissage. Valeur par défaut : |
learning_rate | Réduction de la taille du pas appliquée après chaque arbre pour éviter le surapprentissage. Valeur par défaut : |
max_depth | Profondeur maximale de chaque arbre ; contrôle la complexité du modèle et l’ordre d’interaction. Valeur par défaut : |
min_child_weight | Somme minimale des poids d’instances requise pour créer un nœud feuille. Valeur par défaut : |
gamma | Réduction minimale de la perte requise pour diviser un nœud ; des valeurs plus élevées rendent le modèle plus conservateur. Valeur par défaut : |
subsample | Fraction des lignes d’entraînement échantillonnées par arbre, utilisée pour réduire le surapprentissage. Valeur par défaut : |
colsample_bytree | Fraction de caractéristiques sélectionnées aléatoirement lors de la construction de chaque arbre. Valeur par défaut : |
reg_alpha | Terme de régularisation L1 sur les poids des feuilles ; favorise les solutions clairsemées. Valeur par défaut : |
reg_lambda | Terme de régularisation L2 sur les poids des feuilles ; pénalise les valeurs de poids élevées. Par défaut : |
Source de données
La fenêtre de configuration de la source de données vous permet de spécifier les données utilisées pour l'apprentissage du modèle.
La source de données peut être sélectionnée à gauche. Il existe deux types de sources de données : une source provenant de votre base de données SKOOR ou une requête de données à partir de l’onglet « Data Query ». La sélection de la source de données nécessite des choix supplémentaires, qui peuvent être définis dans la fenêtre, tels que la source de données, la table et les colonnes. Lorsque vous sélectionnez l’option de requête de données, vous devez définir la requête ainsi que les colonnes issues de celle-ci.
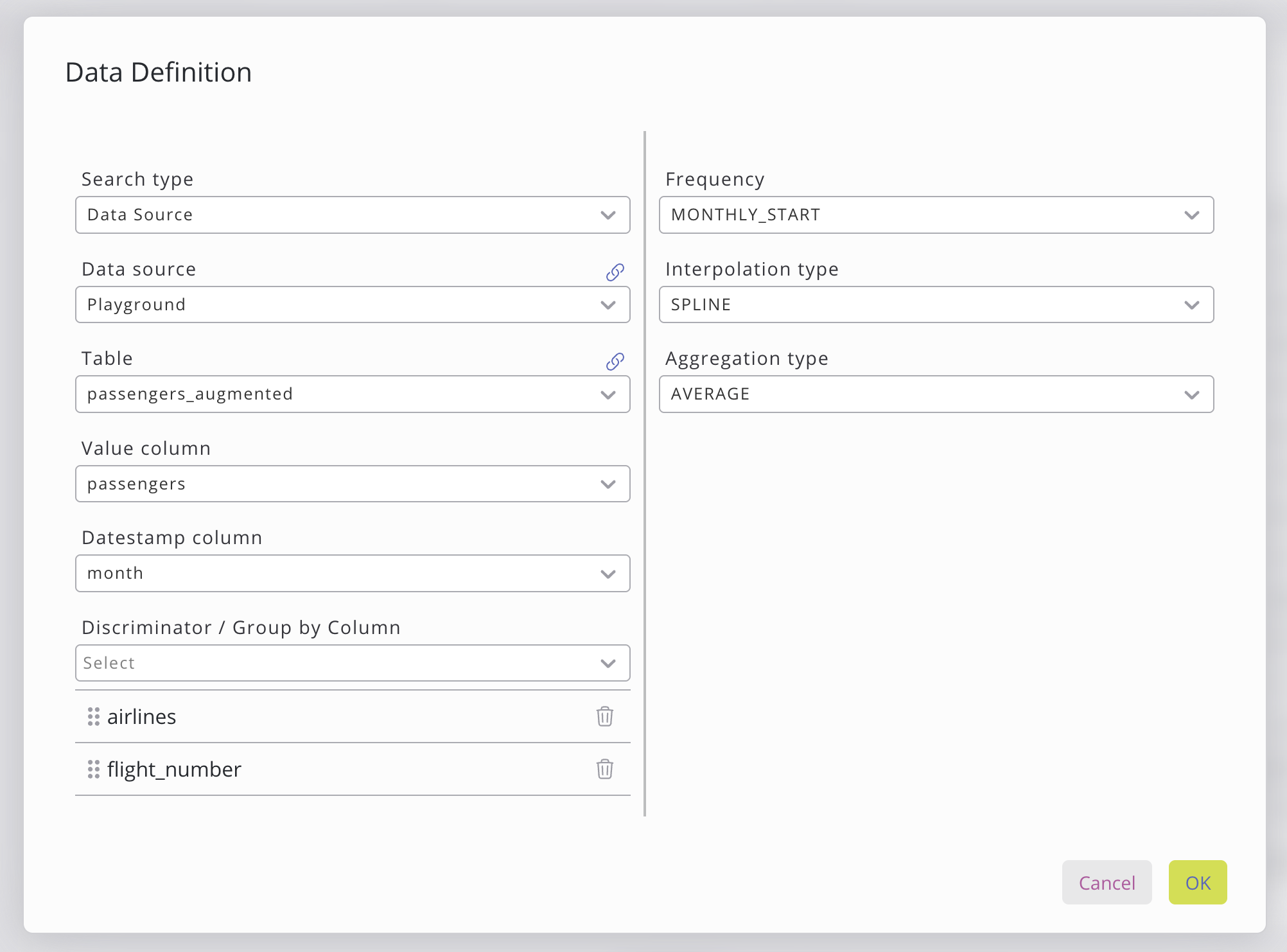
Les colonnes « Valeur », « Horodatage » et « Discriminateur » peuvent être sélectionnées en cliquant sur le menu déroulant. Ce dernier affiche automatiquement les colonnes qui répondent aux critères. Les colonnes suivantes doivent être choisies :
Paramètre | Description |
|---|---|
Colonne de valeur | Doit contenir des valeurs numériques associées à chaque horodatage. |
Colonne « Horodatage » | Les données doivent respecter le format d'horodatage AAAA-MM-JJ HH:mm, et chaque groupe de données doit disposer d'horodatages uniques par groupe (groupes définis par des colonnes discriminantes ou par la structure inhérente des données). |
Colonnes discriminantes | Colonnes facultatives utilisées pour définir le regroupement et la hiérarchie (par exemple : pays → région → ville). Il n’y a pas d’exigences strictes concernant les données, mais l’ordre des colonnes est important, car chaque niveau affine davantage le regroupement. |
Sur le côté droit de la fenêtre de données, il est possible de sélectionner des opérations supplémentaires de prétraitement des données.
Paramètres | Description |
|---|---|
Fréquence | Définit la résolution de sortie de la prévision. Plus d'informations. |
Type d'interpolation | Définit la manière dont les horodatages manquants sont complétés. Plus d'informations. |
Type d'agrégation | Détermine la manière dont plusieurs valeurs d'une même période sont combinées. Plus d'informations. |
Fuseau horaire | Réinitialise l'horodatage dans le fuseau horaire désigné. |
Fréquence
La fréquence détermine la fréquence de sortie des prévisions. Les fréquences suivantes sont disponibles :
Paramètre | Description |
|---|---|
SECONDLY | Prévisions avec une résolution d'une seconde. |
MINUTELY | Prévisions avec une résolution d'une minute. |
TOUTE HEURE | Prévisions avec une résolution horaire. |
QUOTIDIEN | Prévisions avec une résolution quotidienne. |
HEBDOMADAIRE_DIM | Prévisions avec une résolution hebdomadaire, la semaine commençant le dimanche. |
WEEKLY_MON | Résultats des prévisions avec une résolution hebdomadaire, la semaine commençant le lundi. |
WEEKLY_TUE | Résultats des prévisions à une résolution hebdomadaire, la semaine commençant le mardi. |
WEEKLY_WED | Résultats des prévisions à une résolution hebdomadaire, la semaine commençant le mercredi. |
WEEKLY_THU | Résultats des prévisions à une résolution hebdomadaire, la semaine commence le jeudi. |
WEEKLY_FRI | Résultats des prévisions à une résolution hebdomadaire, la semaine commençant le vendredi. |
WEEKLY_SAT | Résultats des prévisions à une résolution hebdomadaire, la semaine commençant le samedi. |
MONTHLY_END | Résultats des prévisions à une résolution mensuelle, ancrés sur le dernier jour du mois. |
MONTHLY_START | Résultats des prévisions à une résolution mensuelle, ancrés au premier jour du mois. |
QUARTERLY_END | Résultats des prévisions à une résolution trimestrielle, ancrés au dernier jour du trimestre. |
QUARTERLY_START | Résultats des prévisions à une résolution trimestrielle, ancrés au premier jour du trimestre. |
YEARLY_END | Résultats des prévisions à une résolution annuelle, ancrés au dernier jour de l'année. |
YEARLY_START | Résultats de prévision à une résolution annuelle, ancrés au premier jour de l'année. |
En interne, la série de données fournie est interpolée ou agrégée à la fréquence définie à l'aide du type d'interpolation et/ou du type d'agrégation. Notez que si vos données comportent des horodatages manquants ou si leur nombre est trop élevé pour la fréquence définie, l'interpolation et/ou l'agrégation sélectionnées sont appliquées automatiquement afin de garantir une prévision fluide.
Types d’interpolation :
Paramètre | Description |
|---|---|
Aucun | Aucune interpolation n’est appliquée, les données sont traitées telles quelles. |
Linéaire | Comble les lacunes en traçant une ligne droite entre les valeurs connues. |
Première | Comble les lacunes vers l'avant en utilisant la dernière valeur connue (remplissage vers l'avant). |
Dernière | Comble les lacunes en amont à l'aide de la valeur connue suivante (remplissage en amont). |
Spline | Comble les lacunes à l'aide d'une courbe cubique lisse ajustée à partir des valeurs connues. |
Types d'agrégation :
Paramètre | Description |
|---|---|
Aucun | Aucune agrégation n'est appliquée, les données sont traitées telles quelles. |
Somme | Additionne toutes les valeurs de chaque période. |
Moyenne | Calcule la moyenne de toutes les valeurs de chaque période. |
Médiane | Renvoie la valeur médiane de toutes les valeurs de chaque période. |
Nombre | Compte le nombre de valeurs non nulles pour chaque période. |
Min | Renvoie la plus petite valeur de chaque période. |
Max | Renvoie la valeur la plus élevée de chaque période. |
Première | Renvoie la première valeur de chaque période. |
Last | Renvoie la dernière valeur de chaque période. |
STD | Calcule l'écart-type de toutes les valeurs de chaque période. |
Fuseau horaire
En interne, tous les horodatages sont réinitialisés selon le fuseau horaire défini par l’utilisateur.
Autorisations
Lecture seule
Lire les résultats des prévisions
Rechercher des configurations de prévision par définition de valeur
Éditeur
Toutes les fonctionnalités du mode « Lecture seule »
Lister toutes les configurations de prévision (vue simple uniquement)
Éditeur de données
Toutes les fonctionnalités de l'éditeur
Droits complets (créer, lire, mettre à jour, supprimer) sur les configurations de prévision et les groupes
Lancer, consulter et annuler des tâches de prévision
Exporter / importer des configurations
Admin
Tout ce que Dataeditor peut faire
Supprimer l'historique des tâches
Affichage des prévisions sur un tableau de bord
Utilisation du widget de prévision par défaut
SKOOR facilite l'accès aux prévisions grâce à un bouton intégré au widget de graphiques. Il suffit de créer un widget de graphique sur le tableau de bord, de définir le type de graphique sur « Mixte » et de configurer les mêmes définitions de données que dans la configuration des prévisions. Après avoir configuré la source de données, cliquez sur « Synchroniser les colonnes » dans la section « Colonnes » en bas à droite de la boîte de dialogue d’édition du widget, ou ajoutez manuellement la colonne pour laquelle des prévisions ont été établies. Cliquez ensuite sur cette colonne et cochez la case « Afficher les prévisions ». Sélectionnez la configuration de prévisions correspondante dans le menu déroulant, puis appliquez les modifications. L’aperçu devrait désormais afficher les données historiques accompagnées des prévisions correspondantes.
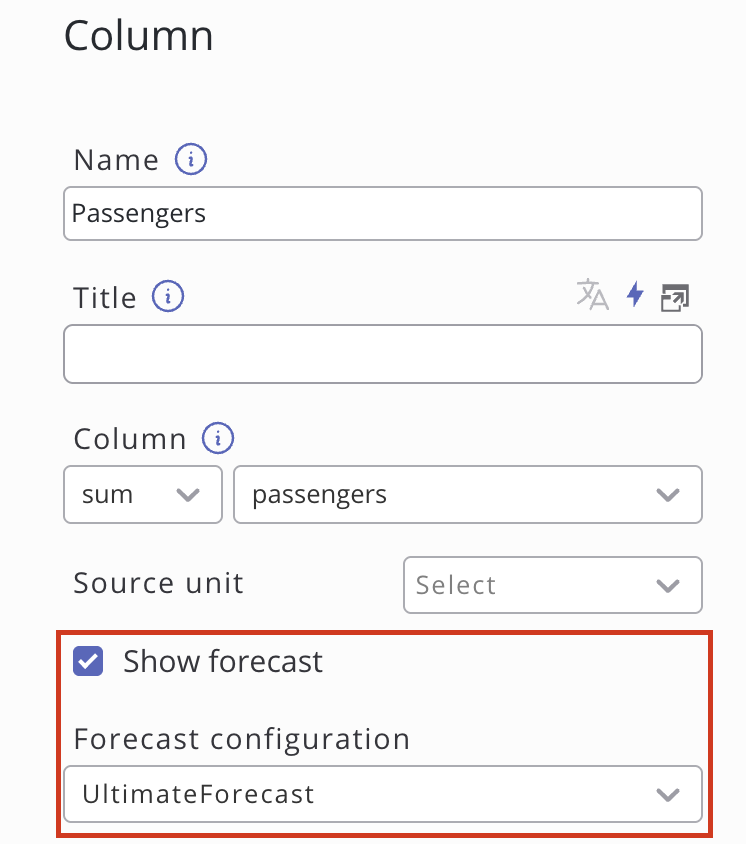
Utilisation d’une requête de données personnalisée
Le tableau contenant les résultats de prévision peut être copié dans le presse-papiers en cliquant simplement sur le bouton « Copier le tableau » dans la page « Général » de la configuration de prévision. À l’aide de ce tableau, vous pouvez accéder aux données de prévision et rédiger votre propre requête de données, par exemple dans SKOOR Studio. Notez qu’il existe des différences dans les colonnes du tableau, comme décrit ci-dessous :
Prophet
Colonne « valeur » (portant le même nom que la colonne de valeur d’entrée)
Colonne d’horodatage (portant le même nom que la colonne d’horodatage d’entrée)
Valeur de confiance inférieure (même nom que la colonne de valeur d’entrée, mais avec « _lower » à la fin)
Valeur de confiance supérieure (même nom que la colonne de valeur d’entrée, mais avec « _upper » à la fin)
Précision
colonnes de discriminateur (nombre de colonnes égal au nombre de colonnes de discriminateur fourni. Noms identiques à ceux des colonnes de discriminateur d’entrée.)
Régression linéaire
Colonne de valeur (Porte le même nom que la colonne de valeur d’entrée.)
colonne d’horodatage (Porte le même nom que la colonne d’horodatage d’entrée.)
précision
colonnes discriminantes (Nombre de colonnes identique au nombre de colonnes discriminantes fourni. Noms identiques à ceux des colonnes discriminantes d’entrée.)
SARIMAX
Colonne de valeur (Porte le même nom que la colonne de valeur d’entrée.)
colonne d’horodatage (Porte le même nom que la colonne d’horodatage d’entrée.)
précision
colonnes discriminantes (Nombre de colonnes identique au nombre de colonnes discriminantes fourni. Noms identiques à ceux des colonnes discriminantes d’entrée.)
XGBoost
Colonne de valeur (Porte le même nom que la colonne de valeur d'entrée.)
colonne d’horodatage (Porte le même nom que la colonne d’horodatage d’entrée.)
précision
colonnes discriminantes (Nombre de colonnes identique au nombre de colonnes discriminantes fourni. Noms identiques à ceux des colonnes discriminantes d’entrée.)