Prognosen
Prognosen
Übersicht
Das Prognosemodul von SKOOR bietet eine auf maschinellem Lernen basierende Vorhersage zukünftiger Trends anhand von Zeitreihendaten. Es stehen vier Modelle zur Verfügung:
Lineare Regression (Offizielle Dokumentation hier)
Alle Modelle unterstützen zeitindexierte Reihen, die direkt aus einer SKOOR-DataSource oder DataQuery stammen.
Prognoseseite
Die Prognoseseite ist in zwei Abschnitte unterteilt.
Allgemeine Seite
Dieser Abschnitt enthält die Einstellungen für die Prognosen.
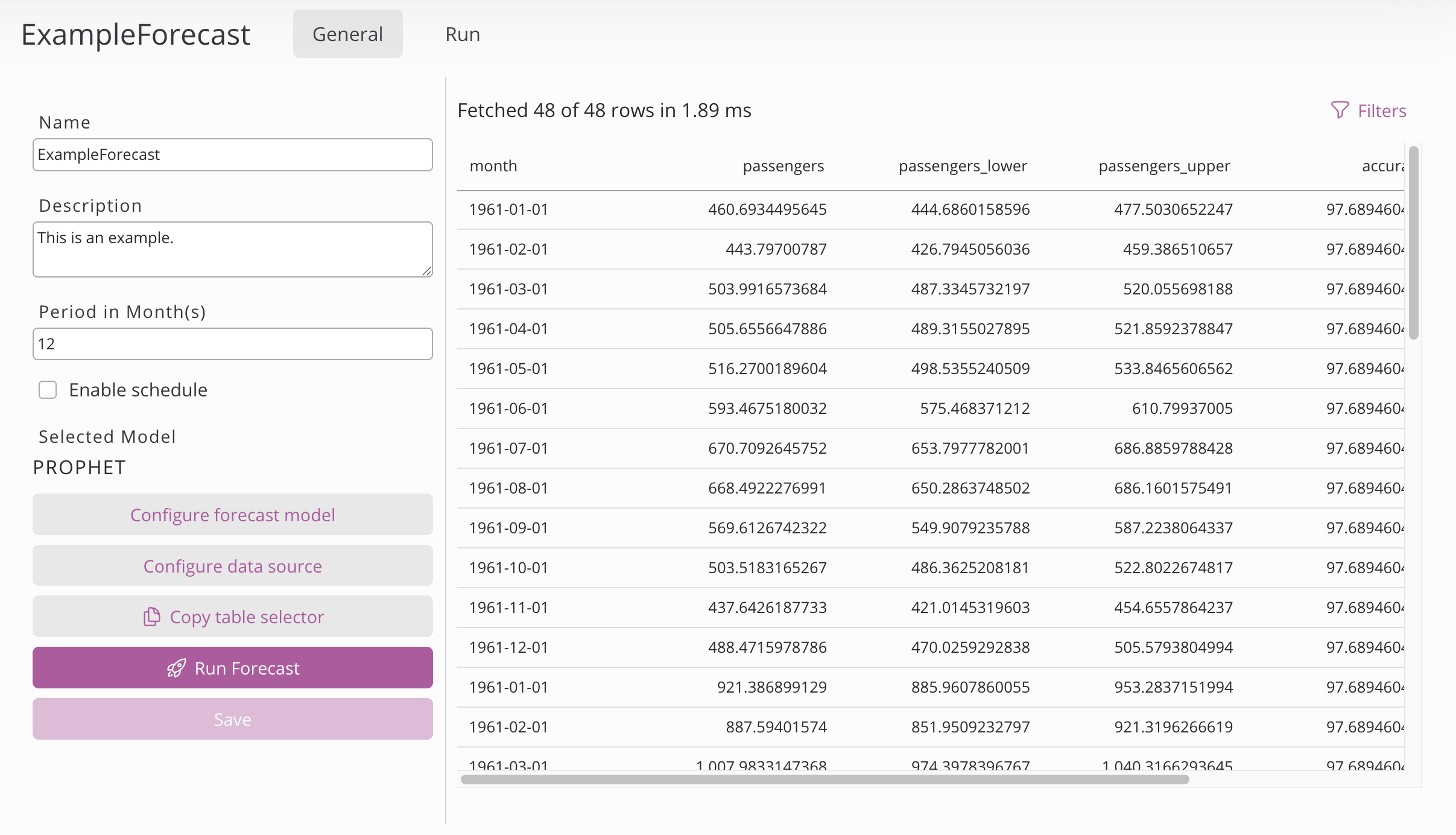
Auf der linken Seite:
Einstellung | Beschreibung |
|---|---|
Name | Name der Prognosekonfiguration. |
Beschreibung | Beschreibung der Prognosekonfiguration. |
Zeitraum | Der Prognosezeitraum legt fest, wie weit in die Zukunft ein Modell Vorhersagen generiert. Ändern Sie die Einheit des Zeitraums in der Datendefinitionskonfiguration. |
Zeitplan aktivieren | Wählen Sie zunächst einen Zeitraum aus (Jahr, Monat, Woche, Tag, Stunde oder Minute) – je nach Ihrer Auswahl werden nur die relevanten Felder angezeigt (Monate, Tagestage, Wochentage, Stunden, Minuten). Eine Mehrfachauswahl ist möglich. Um den Prozess in regelmäßigen Abständen auszuführen, legen Sie den Zeitraum fest und doppelklicken Sie auf die gewünschte Zahl. Beispiel: Täglich um 02:30 Uhr → Periode „Tag“, Stunde 2, Minute 30. Beispiel: Alle 10 Minuten → Zeitraum „Stunde“, Minute <Doppelklick auf 10> |
Ausgewähltes Modell | Das ausgewählte Modell kann in der Konfiguration des Prognosemodells geändert werden. |
Prognosemodell konfigurieren | Wählen Sie das Modell für die Prognose aus. |
Datendefinition konfigurieren | Wählen Sie die Daten für die Prognose aus. |
Tabellenauswahl kopieren | Schaltfläche zum Kopieren der Tabelle, die die Prognose enthält. |
Prognose ausführen | Führt eine Prognose mit den konfigurierten Einstellungen durch. Status und Fortschritt sind auf der Ausführungsseite einsehbar. |
Speichern | Speichert die Prognosekonfiguration. Ist die Option „Hyperparameter-Suche“ im Modellkonfigurator aktiviert, wird beim Speichern automatisch ein Prognose-Lauf ausgelöst. |
Auf der rechten Seite befindet sich die Übersicht über die Prognosedaten in einer Tabelle. Sie wird nur angezeigt, wenn bereits eine Prognose vorliegt.
Ausführungsseite
Dieser Bereich dient der Ausführung und Überwachung der Prognoseläufe. Er bietet Zugriff auf den Verlauf und ermöglicht Einblicke.
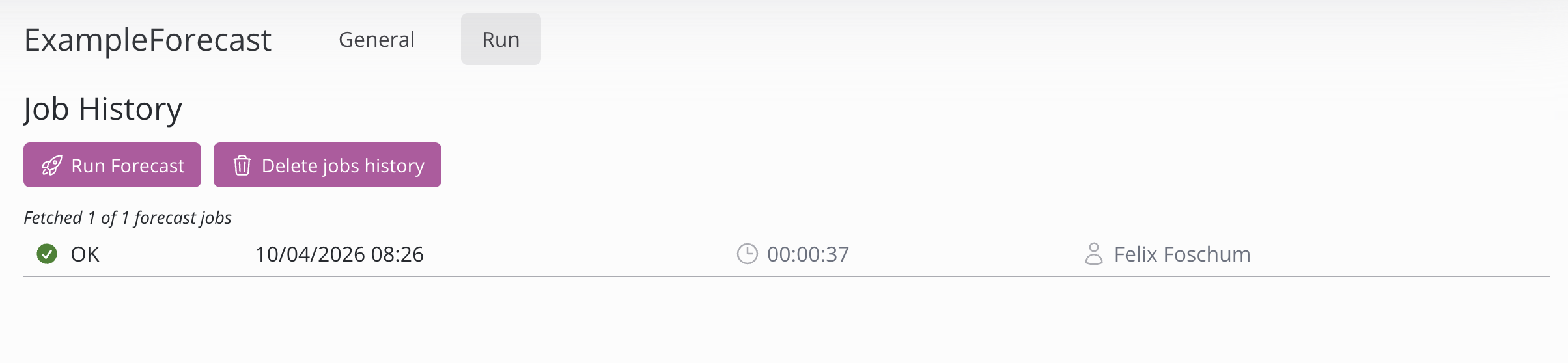
Eine Prognose kann durch Klicken auf die Schaltfläche „Prognose ausführen“ gestartet werden. Der gesamte Verlauf der Läufe kann durch Klicken auf die Schaltfläche „Auftragsverlauf löschen“ gelöscht werden. Beachten Sie, dass alle durch die Prognosen erstellten Tabellen gelöscht werden und Sie die Prognose erneut ausführen müssen, um sie wieder zu erhalten. Wenn ein Job noch läuft, kann er durch Klicken auf das rote X rechts neben dem angezeigten Status abgebrochen werden.
Durch Anklicken eines Auftrags werden die Konsolenausgabe, der Fortschritt, der Status und weitere Informationen angezeigt. In der Konsolenausgabe werden alle Gruppen und deren Genauigkeit ausgegeben. Die angegebene Genauigkeit wird anhand des WAPE (Weighted Absolute Percentage Error) gemessen, in Prozent angegeben und auf der Grundlage der Modellleistung anhand historischer Daten berechnet.
Erstellen einer Vorhersage
Eine Prognosekonfiguration kann entweder durch Klicken auf die Plus-Schaltfläche auf der linken Seite und Eingabe eines Namens oder durch Importieren einer Prognose im JSON-Format erstellt werden. Nachdem eine Prognosekonfiguration erstellt wurde, müssen auf der Seite „Allgemein“ einige Einstellungen vorgenommen werden.
Modellkonfiguration
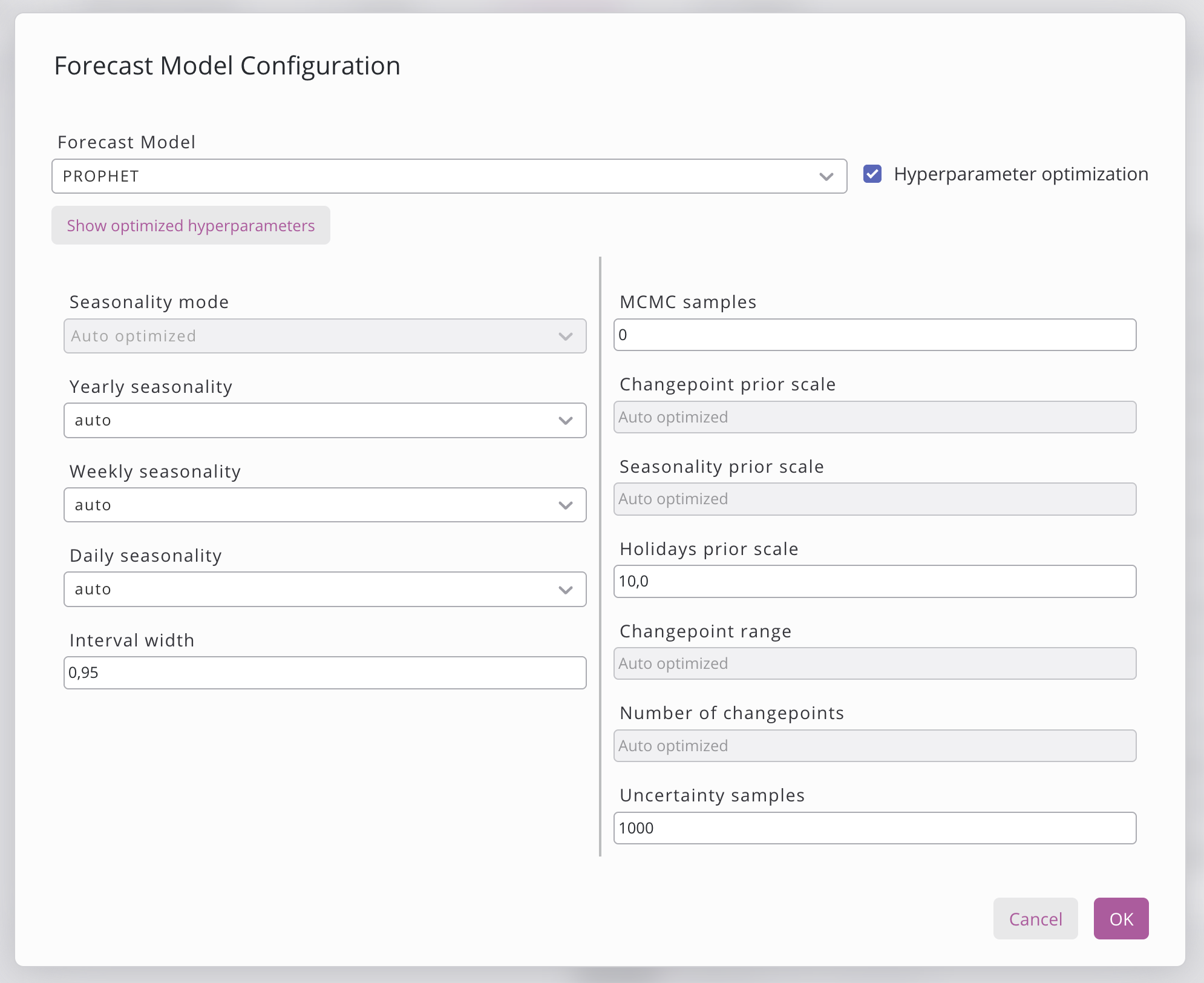
Durch Klicken auf die Schaltfläche „Prognosemodell konfigurieren“ öffnet sich ein Dialogfeld, in dem das Modell ausgewählt werden kann. Derzeit stehen 4 verschiedene Modelloptionen zur Verfügung, die unten aufgeführt sind. Einige der Modelle verfügen über eine Schaltfläche zur Hyperparameter-Optimierung, mit der das Modell verschiedene Kombinationen von Hyperparametern testen kann, um die beste zu finden. Unterhalb des Modells sind verschiedene Hyperparameter aufgelistet, die eingestellt werden können. Wenn die Hyperparameter-Suche bereits gestartet wurde, können Sie die Hyperparameter anzeigen und kopieren, indem Sie auf die Schaltfläche „Optimierte Hyperparameter anzeigen“ klicken.
Wenn Sie die Einstellung der Hyperparameter abgeschlossen haben, klicken Sie auf „Speichern“, um die Modellkonfiguration zu speichern, oder auf „Abbrechen“, um die Änderungen rückgängig zu machen.
Einstellung | Beschreibung |
|---|---|
Prognosemodell | Für die Prognose zu verwendendes Modell:
|
Hyperparameter-Optimierung | Wenn diese Option aktiviert ist, sucht das System automatisch nach optimalen Hyperparametern, indem es verschiedene Einstellungen testet. Dies verlängert die Trainingszeit, verbessert jedoch die Genauigkeit. |
Optimierte Hyperparameter anzeigen | Öffnet ein Dialogfeld, in dem die optimalen Hyperparameter pro Gruppe oder Diskriminator angezeigt werden, die bei der Hyperparameter-Suche ermittelt wurden. |
Die Hyperparameter-Optimierung wird derzeit in Prophet und XGBoost unterstützt.
Folgende Modelle stehen zur Auswahl:
Prophet
Prophet ist ein auf maschinellem Lernen basierendes Open-Source-Tool, das von Meta (ehemals Facebook) für die Prognose von Zeitreihendaten entwickelt wurde. Es ist so konzipiert, dass es robust gegenüber fehlenden Daten und Trendverschiebungen ist, und eignet sich besonders gut für die Prognose von Zeitreihen mit starker Saisonalität. Prophet kann Feiertagseffekte automatisch berücksichtigen und ermöglicht es dem Nutzer, eigene Hyperparameter festzulegen, um die Prognosen noch präziser zu gestalten.
Prophet ist die am häufigsten genutzte der verfügbaren Optionen, da das Training nur mäßig viel Zeit in Anspruch nimmt, das Modell jedoch durchweg die besten Ergebnisse liefert, was es in den meisten Szenarien zur kosteneffizientesten Wahl macht. Prophet zeichnet sich besonders aus, wenn Daten aus mehreren Saisonen vorliegen, in denen wiederkehrende saisonale Effekte, Feiertagseffekte oder unregelmäßige Trendverschiebungen auftreten.
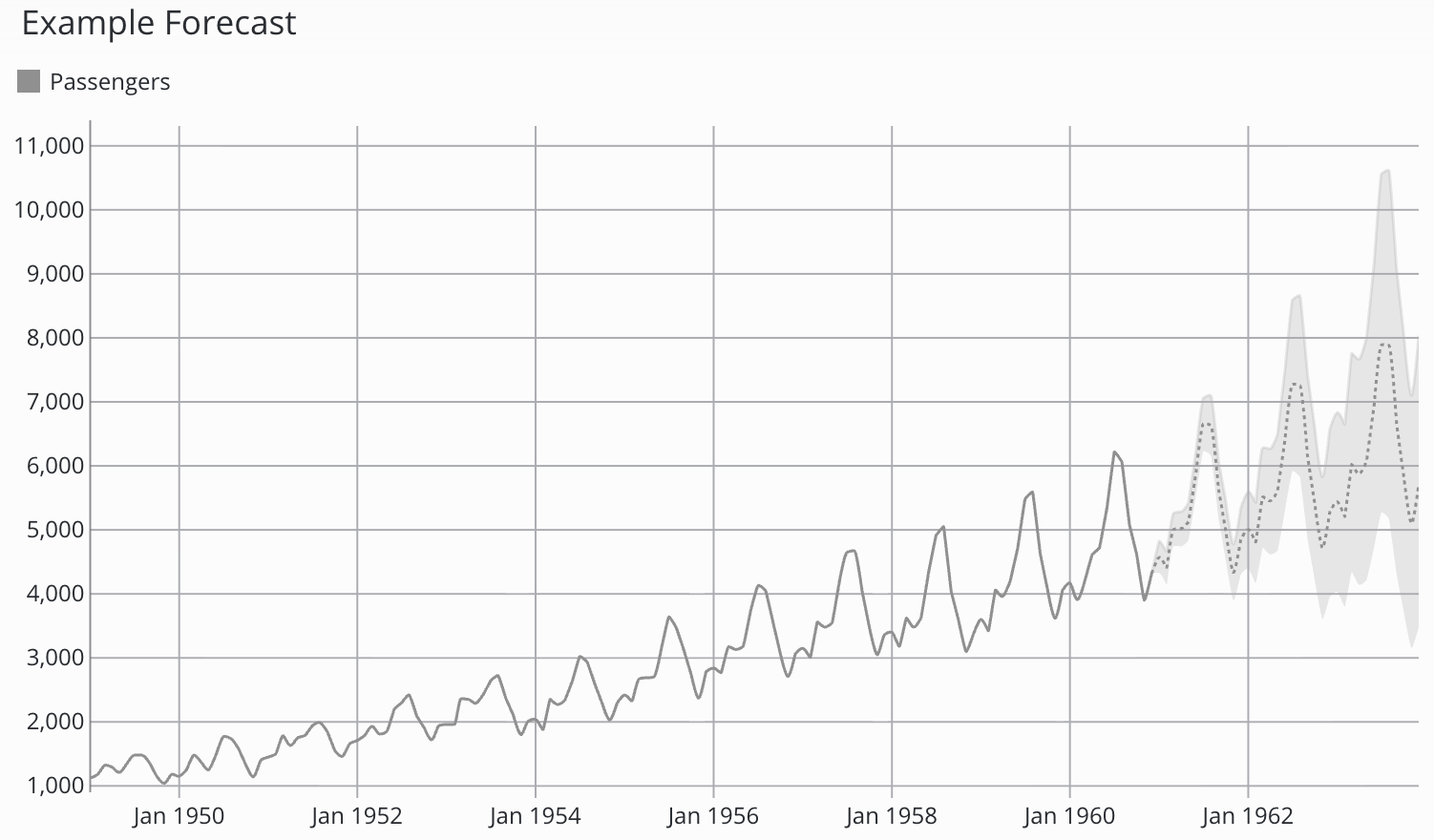
Bei Auswahl des Prophet-Modells werden außerdem Konfidenzintervalle angezeigt, die die Sicherheit des Modells bei seinen Prognosen verdeutlichen. Bei der Visualisierung auf dem Dashboard wird das Konfidenzintervall in einer helleren Farbe um die Prognose herum dargestellt.
Die folgenden Variablen können konfiguriert werden:
Einstellung | Beschreibung |
|---|---|
seasonality_mode | Legt fest, ob saisonale Effekte zum Trend addiert oder mit diesem multipliziert werden. Standard: „ |
yearly_seasonality | Aktiviert, deaktiviert oder erkennt automatisch die Anpassung an ein jährliches saisonales Muster. Standard: |
weekly_seasonality | Aktiviert, deaktiviert oder erkennt automatisch die Anpassung eines wöchentlichen saisonalen Musters. Standard: |
daily_seasonality | Aktiviert, deaktiviert oder erkennt automatisch die Anpassung an ein tägliches saisonales Muster. Standard: |
interval_width | Breite des mit jeder Prognose zurückgegebenen Unsicherheitsintervalls. Standard: |
mcmc_samples | Anzahl der MCMC-Stichproben für eine vollständige Bayes’sche Inferenz; bei 0 wird stattdessen die MAP-Schätzung verwendet. Standard: |
changepoint_prior_scale | Steuert die Trendflexibilität an Wendepunkten; höhere Werte ermöglichen aggressivere Trendwechsel. Standard: |
seasonality_prior_scale | Regularisierungsstärke für saisonale Komponenten; höhere Werte ermöglichen größere saisonale Schwankungen. Standard: |
holidays_prior_scale | Steuert das Ausmaß der Feiertagseffekte auf die Prognose. Standard: |
changepoint_range | Anteil der Trainingshistorie, in dem Trendwechselpunkte auftreten dürfen. Standard: |
n_changepoints | Anzahl potenzieller Trendwechselpunkte, die automatisch in den Trainingszeitraum eingefügt werden. Standard: |
uncertainty_samples | Anzahl der Posterior-Ziehungen, die zur Schätzung der Prognoseunsicherheitsintervalle verwendet werden. Standard: |
SARIMAX
SARIMAX (Seasonal Autoregressive Integrated Moving Average with Exogenous Regressors) ist ein statistisches Modell, das zur Vorhersage zukünftiger Werte auf der Grundlage historischer Daten verwendet wird. Es berücksichtigt sowohl Trends als auch saisonale Muster. Es handelt sich um eine Erweiterung des ARIMA-Modells durch Hinzufügen saisonaler Komponenten.
SARIMAX eignet sich insbesondere dann, wenn die Daten stabil und konsistent generiert werden und ein statistisches Modell einem Modell des maschinellen Lernens vorzuziehen ist.
Im SARIMAX-Modell gibt es keine Variablen, die vom Benutzer angepasst werden können.
Lineare Regression
Die lineare Regression wird verwendet, um Trends zu prognostizieren, indem lediglich eine Gerade an die Trainingsdaten angepasst und diese Gerade in die Zukunft fortgeführt wird. Sie ist ein leistungsstarkes Werkzeug zur Vorhersage zukünftiger Trends in beliebigen Zeitreihendaten.
Die lineare Regression eignet sich am besten, wenn die zugrunde liegenden Daten einen klaren, konsistenten linearen Trend mit minimaler Saisonalität oder minimalem Rauschen aufweisen.
Im Modell der linearen Regression gibt es keine Variablen, die vom Benutzer angepasst werden können.
XGBoost
Das XGBoost-Modell nutzt Gradienten-Boosting-Entscheidungsbäume für die direkte mehrstufige Prognose. Vor dem Training wendet es umfangreiches Feature-Engineering auf die Eingabe-Zeitreihen an, extrahiert dabei Verzögerungsmerkmale, rollierende Statistiken und kalenderbasierte Merkmale und prognostiziert anschließend jeden zukünftigen Zeitpunkt unabhängig.
XGBoost eignet sich am besten für komplexe, nichtlineare Daten. Es kann eine gute Genauigkeit erreichen, benötigt jedoch Zeit für das Training, und in einigen Fällen müssen die Daten zuvor separat vorverarbeitet werden.
Die folgenden Variablen können konfiguriert werden:
Einstellung | Beschreibung |
|---|---|
Ziel | Während des Trainings verwendete Verlustfunktion; legt fest, welche Fehlermetrik das Modell optimiert. Standard: |
quantile_alpha | Zielquantil bei Verwendung der Quantilregression als Zielfunktion. Standardwert: |
n_estimators | Anzahl der zu erstellenden Boosting-Bäume; mehr Bäume erhöhen die Leistungsfähigkeit, bergen jedoch das Risiko einer Überanpassung. Standard: |
learning_rate | Nach jedem Baum angewandte Schrittgrößenreduktion zur Vermeidung von Überanpassung. Standard: |
max_depth | Maximale Tiefe jedes Baums; steuert die Modellkomplexität und die Interaktionsordnung. Standard: |
min_child_weight | Mindestsumme der Instanzgewichte, die zum Erstellen eines Blattknotens erforderlich ist. Standard: |
gamma | Mindestverlustreduktion, die erforderlich ist, um einen Knoten zu teilen; höhere Werte machen das Modell konservativer. Standard: |
subsample | Anteil der pro Baum ausgewählten Trainingszeilen, der zur Verringerung des Überanpassens dient. Standard: |
colsample_bytree | Anteil der Merkmale, die beim Aufbau jedes Baums zufällig ausgewählt werden. Standard: |
reg_alpha | L1-Regularisierungsterm für die Blattgewichte; fördert spärliche Lösungen. Standard: |
reg_lambda | L2-Regularisierungsterm für Blattgewichte; bestraft große Gewichtswerte. Standard: |
Datenquelle
Im Fenster „Datenquelle konfigurieren“ können Sie die Daten festlegen, die zum Trainieren des Modells verwendet werden sollen.
Die Datenquelle kann auf der linken Seite ausgewählt werden. Es gibt zwei Arten von Datenquellen: eine Datenquelle aus Ihrer SKOOR-Datenbank oder eine Datenabfrage über die Registerkarte „Datenabfrage“. Bei der Auswahl der Datenquelle sind weitere Angaben erforderlich, die im Fenster festgelegt werden können, wie z. B. die Datenquelle, die Tabelle und die Spalten. Bei Auswahl der Option „Datenabfrage“ müssen sowohl die Datenabfrage als auch die Spalten aus dieser Datenabfrage festgelegt werden.
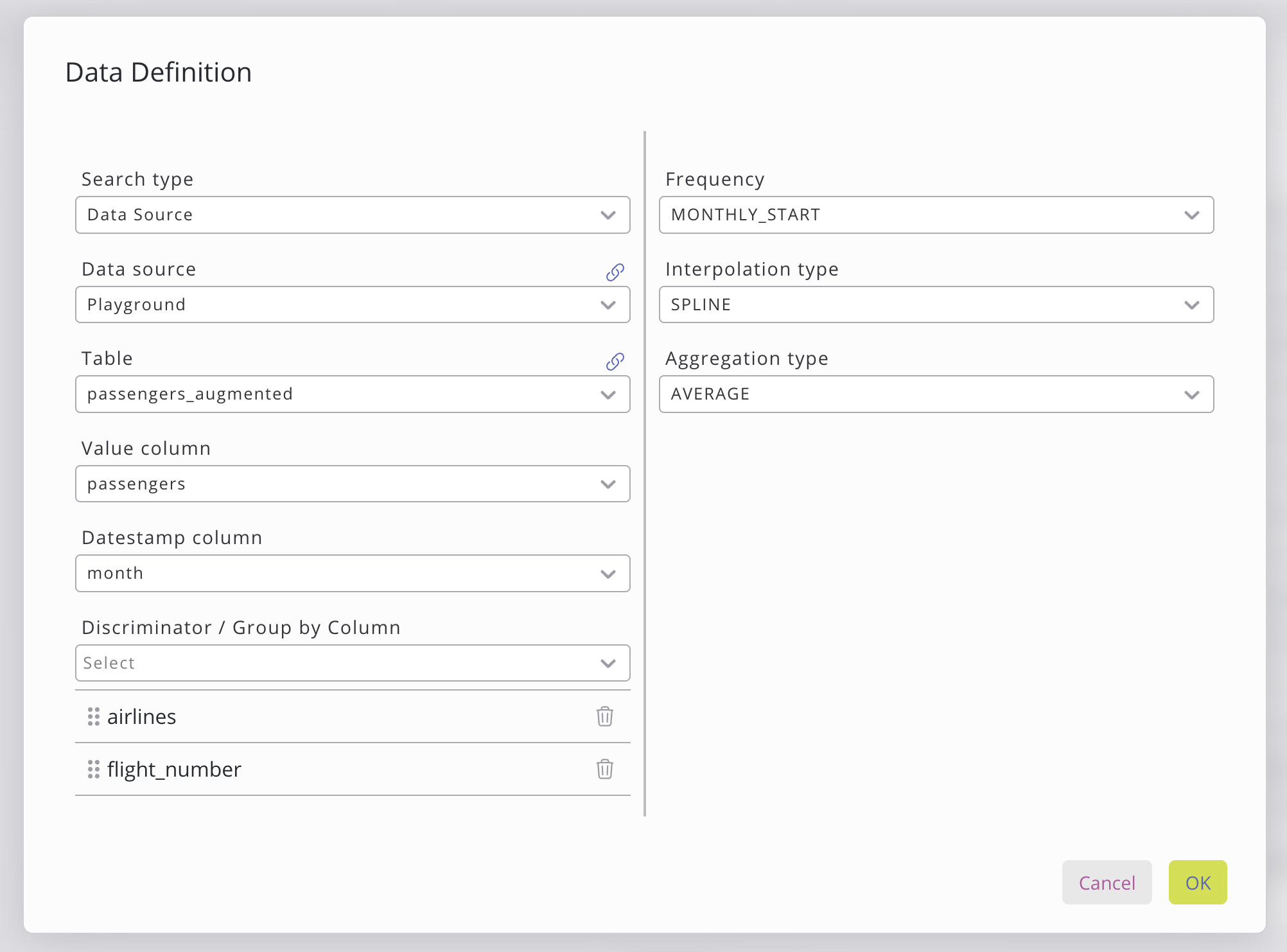
Wert-, Zeitstempel- und Diskriminatorspalten können durch Klicken auf das Dropdown-Menü ausgewählt werden. Das Dropdown-Menü zeigt automatisch Spalten an, die den Anforderungen entsprechen. Folgende Spalten müssen ausgewählt werden:
Einstellung | Beschreibung |
|---|---|
Wertspalte | Muss numerische Werte enthalten, die jedem Zeitstempel zugeordnet sind. |
Zeitstempel-Spalte | Die Daten müssen das Datumsstempel-Format JJJJ-MM-TT HH:mm verwenden, und jede Datengruppe muss gruppenspezifische, eindeutige Zeitstempel aufweisen (Gruppen werden durch Diskriminatorspalten oder die inhärente Datenstruktur definiert). |
Diskriminatorspalten | Optionale Spalten zur Definition von Gruppierungen und Hierarchien (z. B. Land → Bundesland → Stadt). Es gelten keine strengen Datenanforderungen, jedoch ist die Reihenfolge der Spalten von Bedeutung, da jede Ebene die Gruppierung weiter verfeinert. |
Auf der rechten Seite des Datenfensters können weitere Optionen zur Datenvorverarbeitung ausgewählt werden.
Einstellung | Beschreibung |
|---|---|
Häufigkeit | Legt die Ausgabeauflösung der Prognose fest. Weitere Informationen. |
Interpolationsart | Legt fest, wie fehlende Zeitstempel ergänzt werden. Weitere Informationen. |
Aggregationstyp | Steuert, wie mehrere Werte innerhalb eines Zeitraums zusammengefasst werden. Weitere Informationen. |
Zeitzone | Setzt den Zeitstempel in der angegebenen Zeitzone zurück. |
Häufigkeit
Die Häufigkeit legt die Ausgabe der Prognose fest. Folgende Häufigkeiten stehen zur Auswahl:
Einstellung | Beschreibung |
|---|---|
SECONDLY | Prognoseausgabe mit einer Auflösung von einer Sekunde. |
MINUTELY | Prognoseausgabe mit einer Auflösung von einer Minute. |
STÜNDLICH | Prognoseausgabe mit stündlicher Auflösung. |
TÄGLICH | Prognoseergebnisse mit täglicher Auflösung. |
WÖCHENTLICH_SONNTAG | Prognoseergebnisse mit wöchentlicher Auflösung, die Woche beginnt am Sonntag. |
WÖCHENTLICH_MO | Prognoseergebnis mit wöchentlicher Auflösung, die Woche beginnt am Montag. |
WEEKLY_TUE | Prognoseausgabe mit wöchentlicher Auflösung, die Woche beginnt am Dienstag. |
WEEKLY_WED | Prognoseausgabe mit wöchentlicher Auflösung, die Woche beginnt am Mittwoch. |
WEEKLY_THU | Prognoseergebnis mit wöchentlicher Auflösung, die Woche beginnt am Donnerstag. |
WEEKLY_FRI | Prognoseergebnis mit wöchentlicher Auflösung, die Woche beginnt am Freitag. |
WEEKLY_SAT | Prognoseausgabe mit wöchentlicher Auflösung, die Woche beginnt am Samstag. |
MONTHLY_END | Prognoseausgabe mit monatlicher Auflösung, bezogen auf den letzten Tag des Monats. |
MONTHLY_START | Prognoseausgabe mit monatlicher Auflösung, bezogen auf den ersten Tag des Monats. |
QUARTERLY_END | Prognoseergebnis mit vierteljährlicher Auflösung, bezogen auf den letzten Tag des Quartals. |
QUARTERLY_START | Prognoseergebnis mit vierteljährlicher Auflösung, bezogen auf den ersten Tag des Quartals. |
YEARLY_END | Prognoseergebnis mit jährlicher Auflösung, bezogen auf den letzten Tag des Jahres. |
YEARLY_START | Prognoseausgabe mit jährlicher Auflösung, bezogen auf den ersten Tag des Jahres. |
Intern wird die bereitgestellte Datenreihe mithilfe des Interpolationstyps und/oder des Aggregationstyps auf die festgelegte Frequenz interpoliert oder aggregiert. Beachten Sie, dass, falls Ihre Daten fehlende Datumsangaben enthalten oder zu viele Einträge für die gewählte Frequenz aufweisen, die ausgewählte Interpolation und/oder Aggregation automatisch angewendet wird, um eine reibungslose Prognose zu gewährleisten.
Interpolationsarten:
Einstellung | Beschreibung |
|---|---|
Keine | Es wird keine Interpolation angewendet, die Daten werden unverändert verarbeitet. |
Linear | Füllt Lücken, indem eine gerade Linie zwischen bekannten Werten gezogen wird. |
Erste | Füllt Lücken vorwärts unter Verwendung des letzten bekannten Werts (Vorwärtsfüllung). |
Letzter | Füllt Lücken rückwärts unter Verwendung des nächsten bekannten Werts (rückwärtses Ausfüllen). |
Spline | Füllt Lücken mithilfe einer glatten kubischen Kurve, die an die bekannten Werte angepasst wird. |
Aggregationstypen:
Einstellung | Beschreibung |
|---|---|
Keine | Es wird keine Aggregation angewendet, die Daten werden unverändert verarbeitet. |
Summe | Addiert alle Werte innerhalb jedes Zeitraums. |
Durchschnitt | Berechnet den Mittelwert aller Werte innerhalb jedes Zeitraums. |
Median | Gibt den Mittelwert aller Werte innerhalb jedes Zeitraums zurück. |
Anzahl | Zählt die Anzahl der Nicht-Null-Werte innerhalb jedes Zeitraums. |
Min | Gibt den kleinsten Wert innerhalb jedes Zeitraums zurück. |
Max | Gibt den größten Wert innerhalb jedes Zeitraums zurück. |
First | Gibt den ersten Wert innerhalb jedes Zeitraums zurück. |
Last | Gibt den letzten Wert innerhalb jedes Zeitraums zurück. |
STD | Berechnet die Standardabweichung aller Werte innerhalb jedes Zeitraums. |
Zeitzone
Intern werden alle Zeitstempel auf die vom Benutzer festgelegte Zeitzone zurückgesetzt.
Berechtigungen
Nur-Lese-Zugriff
Prognoseergebnisse lesen
Prognosekonfigurationen nach Wertdefinition suchen
Bearbeiter
Alle Funktionen der Berechtigungsstufe „Nur Lesen“
Alle Prognosekonfigurationen auflisten (nur einfache Ansicht)
Dateneditor
Alle Funktionen des Editors
Vollständige Rechte (Erstellen, Lesen, Aktualisieren, Löschen) für Prognosekonfigurationen und Gruppen
Prognoseaufträge starten, anzeigen und abbrechen
Konfigurationen exportieren/importieren
Admin
Alle Funktionen des Dataeditors
Auftragsverlauf löschen
Anzeigen der Prognose auf einem Dashboard
Verwendung des Standard-Prognose-Widgets
SKOOR ermöglicht einen einfachen Zugriff auf die Prognose durch die Einführung einer Schaltfläche im Diagramm-Widget. Erstellen Sie einfach ein Diagramm-Widget auf dem Dashboard, stellen Sie den Diagrammtyp auf „Gemischt“ ein und konfigurieren Sie dieselben Datendefinitionen wie in der Prognosekonfiguration. Nachdem Sie die Datenquelle eingerichtet haben, klicken Sie entweder im Bearbeitungsdialog des Widgets unten rechts im Abschnitt „Spalten“ auf „Spalten synchronisieren“ oder fügen Sie die Spalte, für die eine Prognose erstellt wurde, manuell hinzu. Klicken Sie anschließend auf diese Spalte und aktivieren Sie das Kontrollkästchen „Prognose anzeigen“. Wählen Sie die passende Prognosekonfiguration aus dem Dropdown-Menü aus und klicken Sie auf „Übernehmen“. Nun sollte die Vorschau bereits die historischen Daten zusammen mit der entsprechenden Prognose anzeigen.
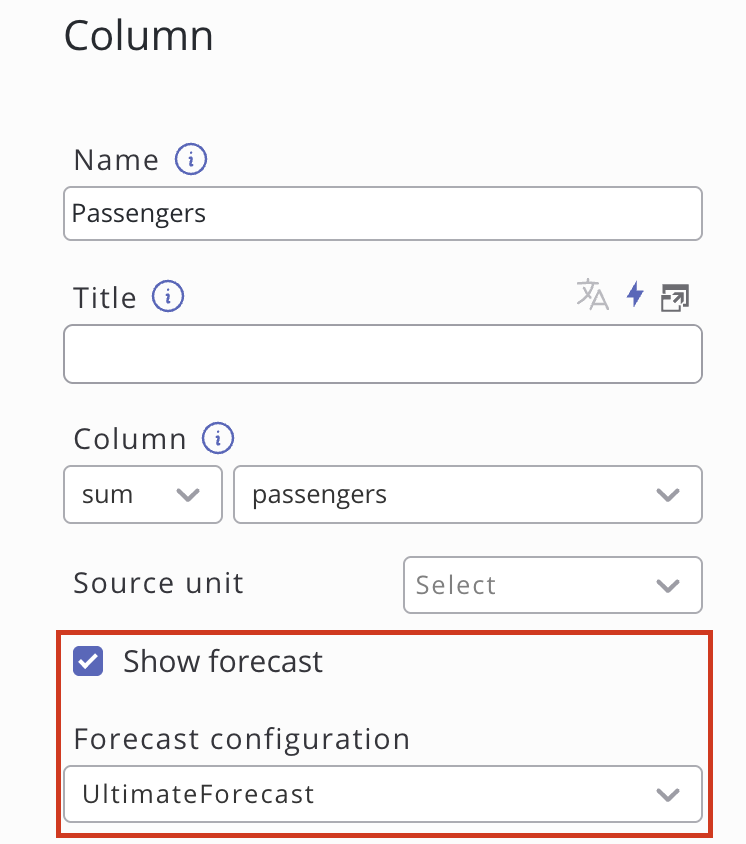
Verwendung einer benutzerdefinierten Datenabfrage
Die Tabelle mit den Prognoseergebnissen kann durch einfaches Klicken auf die Schaltfläche „Tabelle kopieren“ auf der Seite „Allgemein“ der Prognosekonfiguration in die Zwischenablage kopiert werden. Mithilfe dieser Tabelle können Sie auf die Prognosedaten zugreifen und Ihre eigene Datenabfrage erstellen, z. B. im SKOOR Studio. Beachten Sie, dass es Unterschiede bei den Tabellenspalten gibt, wie beschrieben:
Prophet
Wertespalte (Trägt denselben Namen wie die Eingabewertspalte.)
Datumsstempel-Spalte (Trägt denselben Namen wie die Eingabe-Datumsstempel-Spalte.)
Spalte „Unterer Konfidenzwert“ (Trägt denselben Namen wie die Eingabespalte „Wert“, endet jedoch mit „_lower“.)
Oberer Konfidenzwert (Trägt denselben Namen wie die Eingabewert-Spalte, endet jedoch mit „_upper“.)
Genauigkeit
Diskriminatorspalten (Anzahl der Spalten entspricht der Anzahl der angegebenen Diskriminatorspalten. Namen entsprechen denen der Eingabediskriminatorspalten.)
Lineare Regression
Wertspalte (Trägt denselben Namen wie die Eingabewertspalte.)
Datumsstempel-Spalte (Trägt denselben Namen wie die Eingabe-Datumsstempel-Spalte.)
Genauigkeit
Diskriminatorspalten (Die Anzahl der Spalten entspricht der Anzahl der angegebenen Diskriminatorspalten. Die Spaltennamen entsprechen denen der Eingabe-Diskriminatorspalten.)
SARIMAX
Wertspalte (Trägt denselben Namen wie die Eingabewertspalte.)
Datumsstempel-Spalte (Trägt denselben Namen wie die Eingabe-Datumsstempel-Spalte.)
Genauigkeit
Diskriminatorspalten (Die Anzahl der Spalten entspricht der Anzahl der angegebenen Diskriminatorspalten. Die Spalten tragen dieselben Namen wie die Eingabe-Diskriminatorspalten.)
XGBoost
Wertspalte (Trägt denselben Namen wie die Eingabewertspalte.)
Datumsstempel-Spalte (Trägt denselben Namen wie die Eingabe-Datumsstempel-Spalte.)
Genauigkeit
Diskriminatorspalten (Die Anzahl der Spalten entspricht der Anzahl der angegebenen Diskriminatorspalten. Die Spalten haben dieselben Namen wie die Eingabe-Diskriminatorspalten.)